周刊第16期: Andrej Karpathy 讲 AI
软件3.0, 深入理解大模型, 如何使用大模型
本文为周刊第16期,前期的周刊参见:周刊系列。
TL;DR 本期周刊介绍 Andrej Karpathy 的三次演讲/YouTube视频课程,通过对这些视频的解读,主要阐述下面三个系列的问题:1. 为什么说我们处在软件3.0?它跟软件2.0和1.0的区别是什么?为什么说大模型相比基建(电网),更像是操作系统,而且还是1960年代的操作系统?2. ChatGPT是怎么被训练出来的?预训练、监督微调、强化学习是什么关系?分别对大模型产生了哪些影响?大模型未来的发展方向是什么?3. ChatGPT的能力边界是什么?业界那么多AI应用的差别是什么?除了聊天对话还能用它们干啥?
Andrej Karpathy 是一位出生在捷克斯洛伐克的AI计算机科学家,博士毕业于斯坦福,师从李飞飞。毕业后成为OpenAI的创始成员。2017年加入特斯拉,成为其人工智能总监,领导特斯拉智能驾驶的机器视觉团队。2023年返回OpenAI,不到一年后决定创业,方向是AI教育领域。按照他自己的说法,教育是他热爱的事业。也确实如此,在斯坦福期间,他创作并担任主讲的课程《CS 231n:卷积神经网络在视觉识别中的应用》,一度成为该校学生规模最大的课程。而他在YouTube上发布的AI教学视频也深受网友喜爱。

本期周刊将介绍他的最新一次演讲及两则YouTube教学视频。
软件3.0
今年6月17日,Andrej Karpathy 在 Y Combinator AI Startup School (与会者还有奥特曼、李飞飞、马斯克等人)上发表了名为 Software is Changing (Again) 的演讲,提出了 软件3.0(Software 3.0)的概念。Andrej Karpathy擅长提出一些新概念,比如之前的Software 2.0 和 vibe coding(氛围编程)。下面简要总结下他的演讲。
软件从诞生之后的70年里,在根本层面上并没有太大的变化,但在过去的几年,却发生了两次根本性的改变。
软件1.0时期,大量的软件都由人来编写,在GitHub上,存储了不同类型的软件仓库,可以将它看成是一个大的“软件地图”。“软件1.0”是程序员为计算机编写的代码。
软件2.0时期,不需要直接写代码了。“软件2.0”基本上是神经网络,或者说神经网络中的权重参数(weights)。软件2.0时代的GitHub是什么呢?Andrej Karpathy 认为是 Hugging Face. 在这里能看到那些软件(模型)。

现在,我们进入了一个新的时期,神经网络也可以编程了,或者可以将神经网络看成是可编程的计算机,而运行在其上的编程语言则是提示词(prompts),这种编程语言可以用英语(或其他人类语言)来写。
举个例子,如果要实现情感分类这一个任务,那么:
- 软件1.0时期,可以写一段Python代码来实现;
- 软件2.0时期,可以训练一个神经网络模型;
- 软件3.0时期,可以通过提示词(prompt)来指挥大模型完成任务。
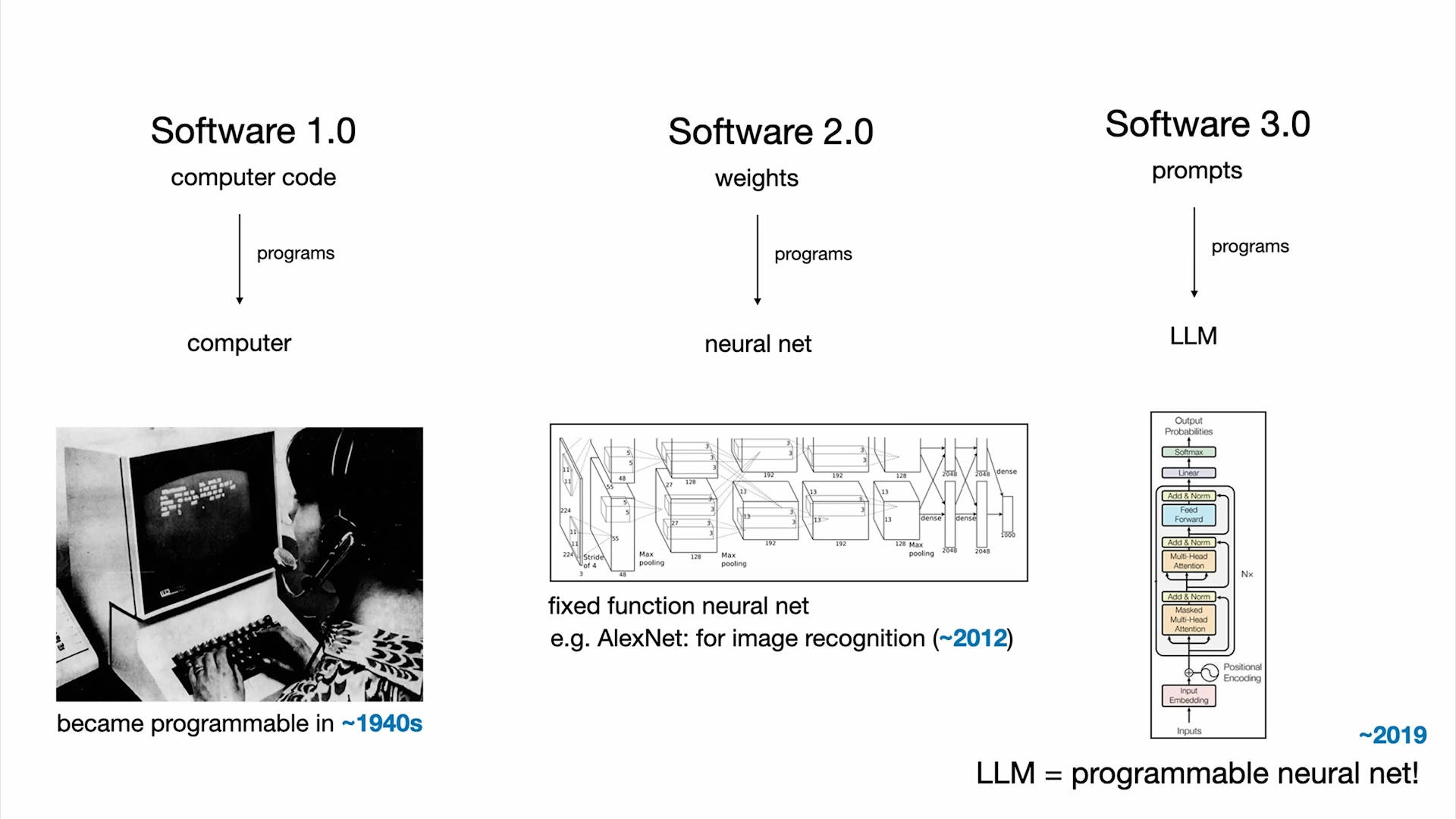
我们处在软件3.0时期,而大家可能也已经注意到了,GitHub上的很多代码,已经不再是传统意义上的代码了,里面夹杂了大量的英文。这是一个正在增长的全新编程范式,我们在用日常使用的语言来编程。
有人说:AI是新电网,确实如此,大模型给人的感觉就像是一种基础设施。那些大模型厂商,如OpenAI、Gemini、Anthropic等,这些公司投入大量的资本开支(CAPEX)去训练大模型,就是在建设一张新“电网”。然后他们通过API向用户提供智能服务,又投入持续的运营开支(OPEX),本质上就像是电力公司把电输送到千家万户一样,把智能输送给每个人。
用户则按使用量计费来使用大模型服务,比如按百万token来付费,这跟我们使用水电的逻辑是一样的,而作为用户,我们也会对这些API服务提出类似公共事业的需求,低延迟、高安全、高可用等等。一旦这些公共基础设施发生故障,影响也是严重的,就像电力故障会导致工厂停工一样,大模型的宕机也可能导致我们陷入无法工作的状态。(我在写这则周刊时,刚好看到网上有关于Claude Code故障导致程序员无法工作的吐槽。主管问程序员那没有Claude Code之前是怎么干活的?程序员则回怼:开玩笑吗?难道我们今天还要像野蛮人一样自己一行一行写代码?)
不过相比于“电网”,Andrej Karpathy 认为大模型更恰当的类比是“操作系统”。因为它不是单纯的商品,而是生态的核心。像操作系统一样,大模型有开源也有闭源,有很多家提供厂商,最终可能会演进成少量的几个生态。LLM本身就像是CPU,上下文窗口则像内存,大模型应用通过调度这种“CPU”和“内存”来解决问题。
我们现在部署大模型的资源成本很高,这很像1960年代的大型机时代,所以大模型都被集中部署在了云端,用户只能够通过API来调用它,就像当年要使用瘦客户端去接入大型机一样。没有人能独享大型机,所以产生了分时技术,而今天我们对大模型的使用如出一辙。大模型的PC(个人电脑)时代还没有到来,从目前的经济性来看还不允许,但未来会是这个趋势。 另外,我们与大模型的交互通过 ChatBox 的文本交互,这也很像计算机时代初期只能通过终端命令行进行交互,属于大模型的通用 GUI(图形界面)交互方式还没有被发明出来。

不过,在一些特定场景下的GUI交互有应用了,比如在编码领域,Cursor 就是一个例子。大家都知道,大模型能力很强,几乎包含了所有公开的人类知识,但同时又存在幻觉等严重问题,对此,在特定场景下的交互设计则尤为重要,以规避他的缺陷,又可以同时享受它的超能力。Andrej Karpathy 把 Cursor 这类应用叫作“半自主应用”(Partial Autonomy Apps), 即保留传统界面,让人类可以手动完成所有工作,同时由集成大模型,更高效的完成更复杂的工作。在Cursor中,它给用户提供了多种选项来控制自主程度:
- Tab 补全:用户掌握主导,大模型轻微辅助。
- 选中代码按 Ctrl+K: 让大模型改一小段,自主程度适中。
- Ctrl+L: 改整个文件,让大模型做的更多。
- Ctrl+I: 放手让它改整个项目目录,完全交给大模型。
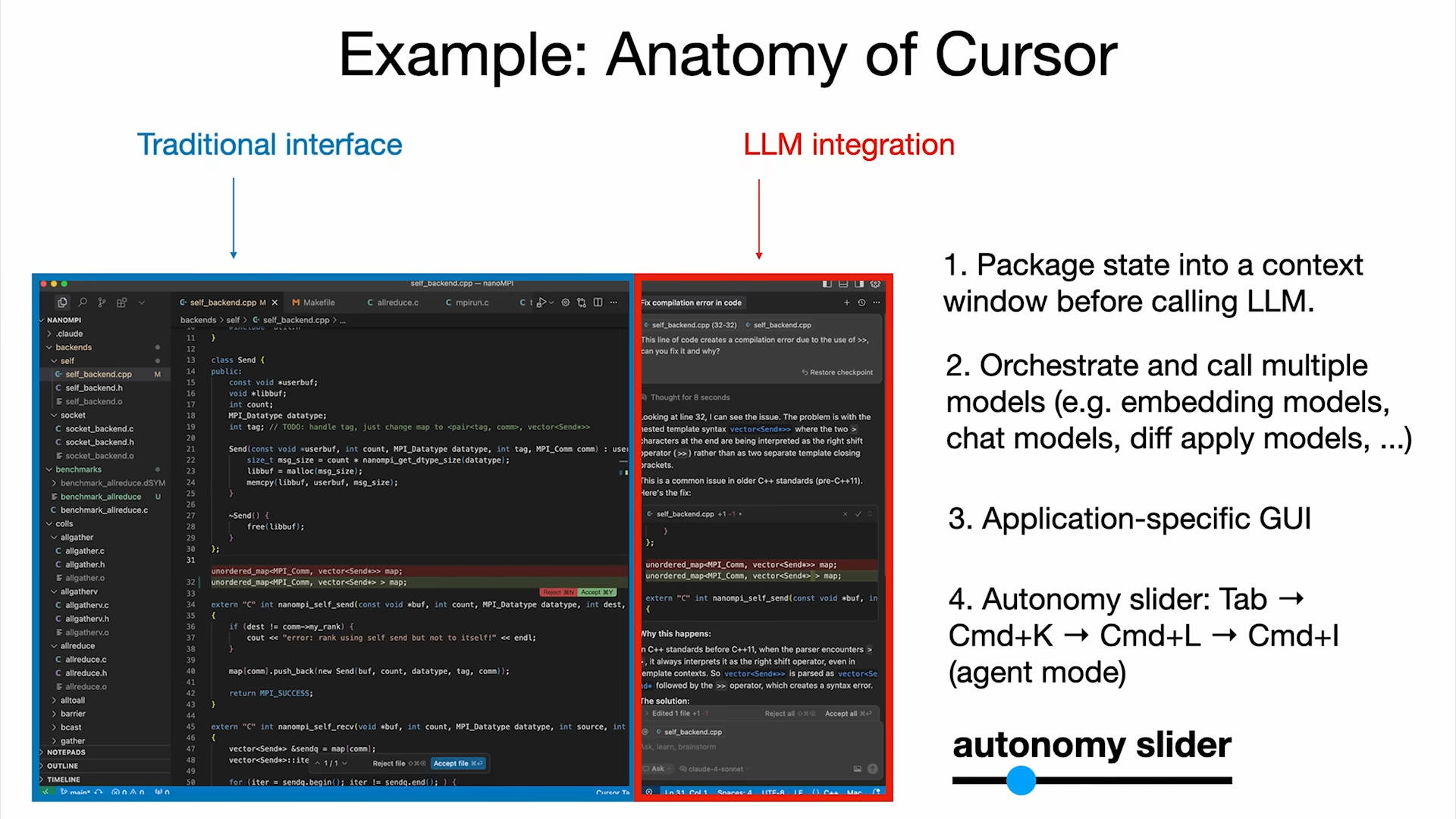
实际上,在真正的业务场景,并不是大模型越自主越好。AI太过主动,有时反而会拖慢效率。就像钢铁侠的战衣一样,它具备自主执行任务的能力,但更多的场景,是斯塔克在操作着它。在当下大模型还不完善的情况下,半自主Agent是比较合适的选择。
总结一下,我们处在软件3.0的时代,有大量的代码需要重写,而重写的语言将是人类语言。大模型不仅像是“电网”,更像是操作系统,而现在的阶段则是1960年代操作系统刚起步的时候,这是绝佳的时机。
深入理解大模型
今年年初,Andrej Karpathy 在 YouTube 上发布了一则三个半小时的视频,名为 Deep Dive into LLMs like ChatGPT, 深入浅出地讲解了大模型的原理。以打造ChatGPT为例,从预训练(Pre-training)、微调(SFT)和强化学习(RL)三个方面来讲解大模型的构建过程。为了节省大家的时间,这里将三个半小时的视频内容总结成如下6000字左右的文本。
本视频适合对神经网络有入门基础的人学习,如果希望学习神经网络入门知识,欢迎参阅拙作《从神经网络到 Hugging Face: 神经网络和深度学习简史》。
预训练 Pre-training
大模型是通过预训练得到的。预训练分为以下几步:
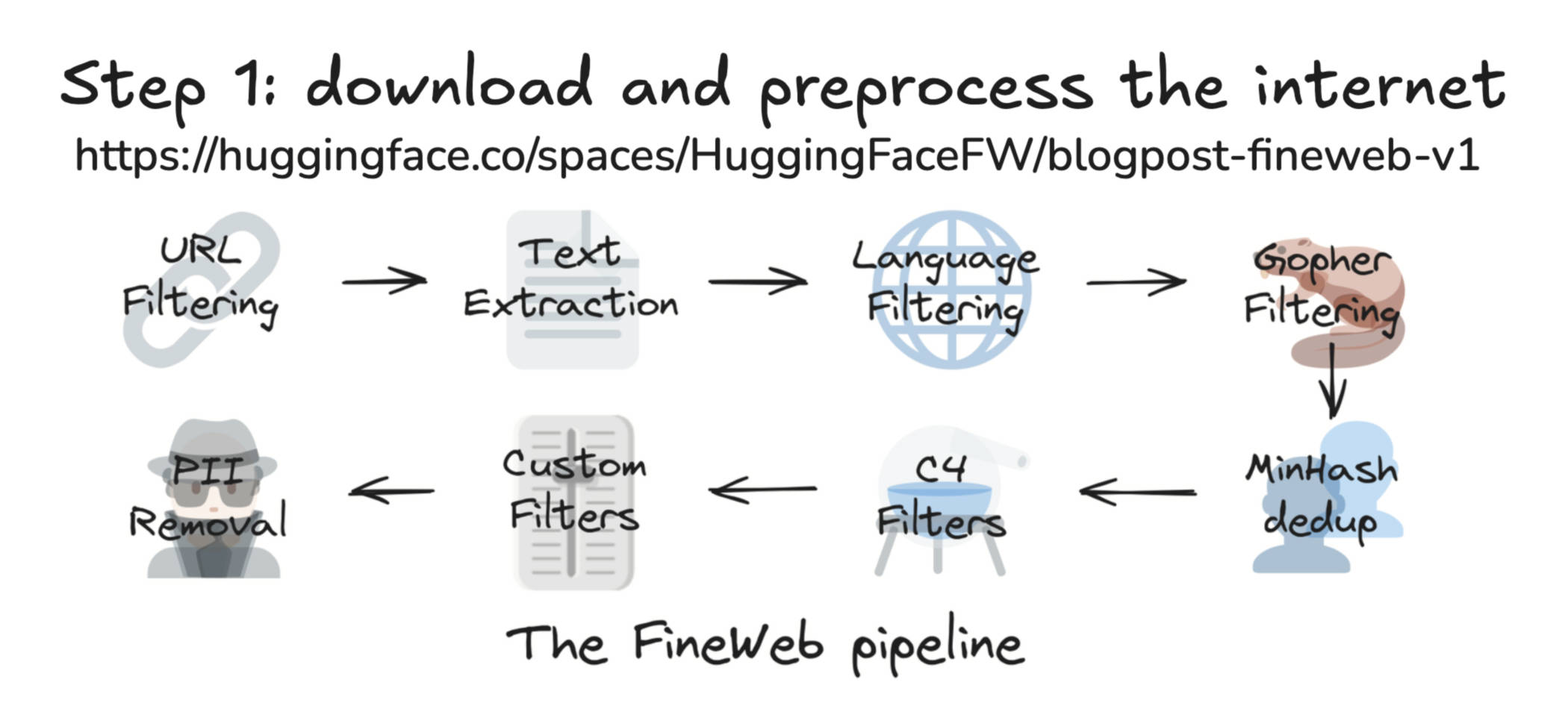
1、下载并处理互联网数据: 比如Hugging Face收集整理并开源的 FineWeb 数据集,收集了互联网上公开可用的高质量文本数据,经过清洗、筛选,最终只有44TB量级。这个过程是这样的:首先是从互联网上爬取数据,Common Crawl 这个组织从2007年开始持续扫描互联网,到2024年已经索引了27亿个网页,Common Crawl 爬取的这份数据是原始的互联网数据。接下来便要经过大量的过滤和清洗工作:URL过滤(排除一些黑名单网站)、文本抽取(从原始的HTML网页中提取纯文本内容)、语言过滤(如FineWeb专注英文因此主要保留英文内容)、去重、PII信息移除(剔除个人隐私数据),然后才能得到像FineWeb这样的数据集。
2、tokenization: 第二步是将这些文本数据输入进神经网络,如果直接将文本的UTF-8编码输入给大模型,这些原始的二进制bit序列将非常长,会浪费神经网络的资源。因此,一般采用对连续bit分组进行编码,比如一个单词或一个emoji,这样就可以压缩序列长度。实际场景中还会使用一些优化方法,比如字节对编码方法(Byte-Pair Encoding, BPE),就是针对数据里高频出现的连续符号组合进行编码,比如 "mac"的编码是116,"book"编码是32,116,32对("macbook")经常出现,可以给它一个新的编码 256 来替换。这种将原始文本转换成符号(token)序列的过程就是 Tokenization.
3、神经网络训练: 这是计算最密集的工作阶段,所有训练大模型的算力消耗基本上集中在这里。训练阶段的主要目标,就是建模token在序列里是如何关联、彼此衔接的规律,换句话说,就是让大模型学会在一个token序列里,什么样的token更有可能出现在另一个token之后。大模型的数据就是一段长度的token序列(这个长度被称为窗口),而输出则是对下一个token的预测。因此,训练大模型就变成了通过数学方法,更新大模型,让大模型对正确token的预测概率更高,对错误token的概率更低。这里面的数学方法主要是向量计算。
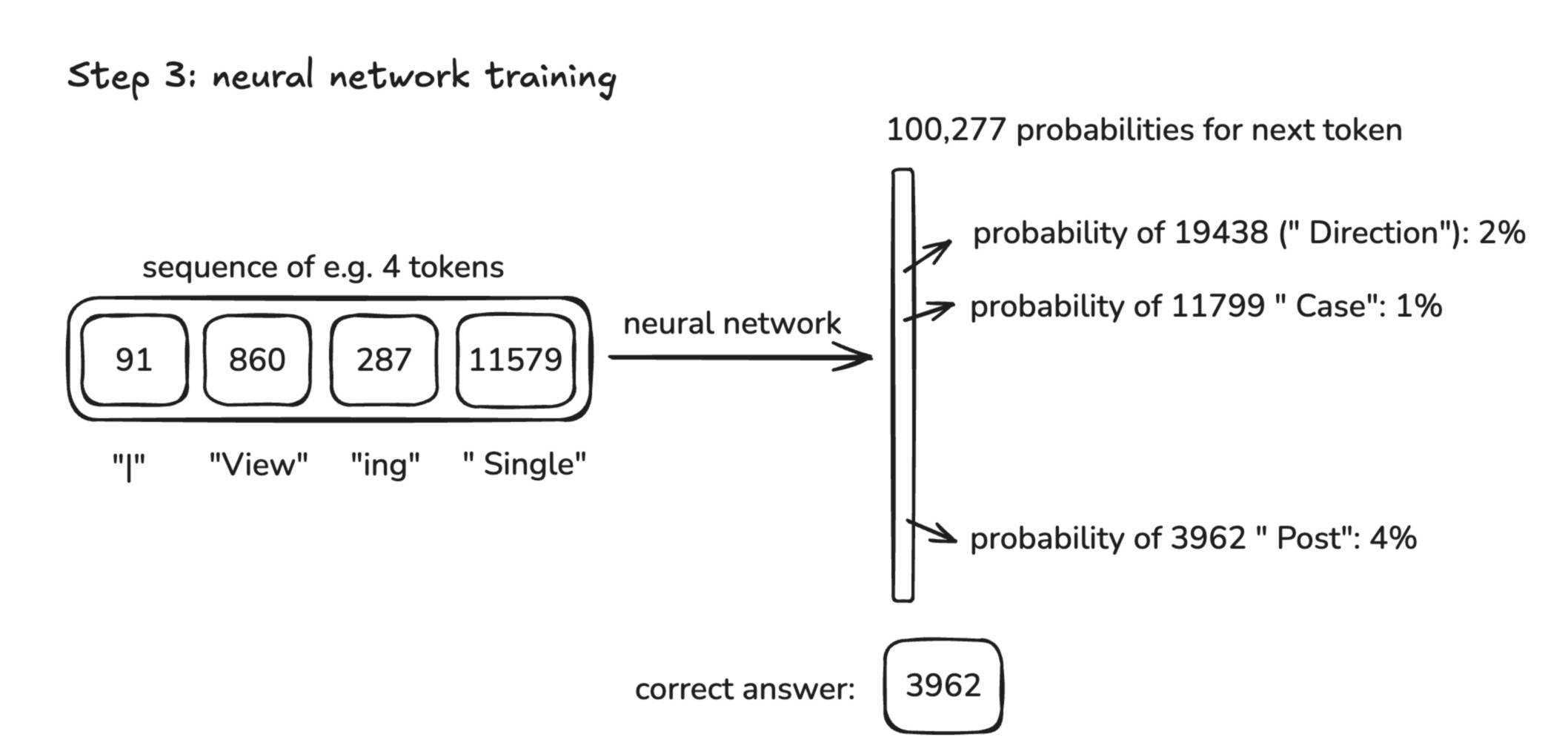
4、推理: 前面讲的是大模型的学习过程,而推理则是大模型生成内容的过程。推理过程大概是这样:提供给大模型一些起始token,大模型返回一组概率分布,然后根据高概率采样获得的下一个token结果反馈给大模型,继续得到下一个token,不停重复这一过程,最终生成一段文本。

以上就是大模型的训练和推理过程。
GPT-2在2019年发布,跟当前的GPT-4在基本架构上没有本质区别。它有16亿个参数,上下文长度只有1024,也就是说从数据集中采样窗口时不会超过1024个token. 训练GPT-2的数据集规模是一千亿个token, 相比之下,FineWeb的数据集token总量上15万亿。2019年OpenAI训练GPT-2的成本估计约为4万美元,而今天复刻一个GPT-2仅需一天时间,成本估计100美元。原因是数据集质量更高,更重要的是硬件算力飞速提升了。
相比之下,更新的Llama 3 则规模大得多,4050亿参数,15万亿token的训练数据。在Meta发布Llama 3的技术论文中详细说明了其训练过程。
GPT-4、Llama 3 都属于基础模型(Base Model),还不能直接作为对话助手模型使用,而ChatGPT模型被叫作 Instruct 模型,被用来做对话模型。如果我们在对话中直接使用基础模型,会发现根本用不起来。使用网站 Hyperbolic 可以在线体验这些基础模型,当用户输出问题时,发现它会随机的输出一些结果,因为它不是在回答问题,而是在做自动补全。可以把基础模型理解成一个拥有大量知识的人,按照统计规律给这些知识建模,给他一些信息输入,他便从记忆里复述知识内容,但会因为概率性统计而出现“记忆偏差”。
监督微调 Supervised Fine-Tuning
1、怎么做SFT?
要想让基础模型变成可以对话的助手,让它能够回答问题,进行多轮对话,并理解意图,就需要后训练处理。
后训练方法有多种,典型的有监督微调(SFT)。在SFT中,训练数据集从互联网数据变成了由人工标注的数据,让模型学习如何在对话中回答人类问题。比如如下这条语料:
Human: Why is the sky blue?
Assistant: The sky appears blue because of Rayleigh scattering...当它被tokenization后,模型看到的是token ID,并不理解它是对话。因此,一般大模型厂商会采用一些内部的特殊编码来标识出对话格式。比如 GPT-4 会用如下特殊token来标记对话结构: IAM_START 表示发言开始,IAM_END 表示发言结束,IAM_SEP 用于内部分隔,USER / ASSISTANT 表示谁在说话。用户问 "What is 2 + 2?" 会被编码成token序列 <IAM_START>
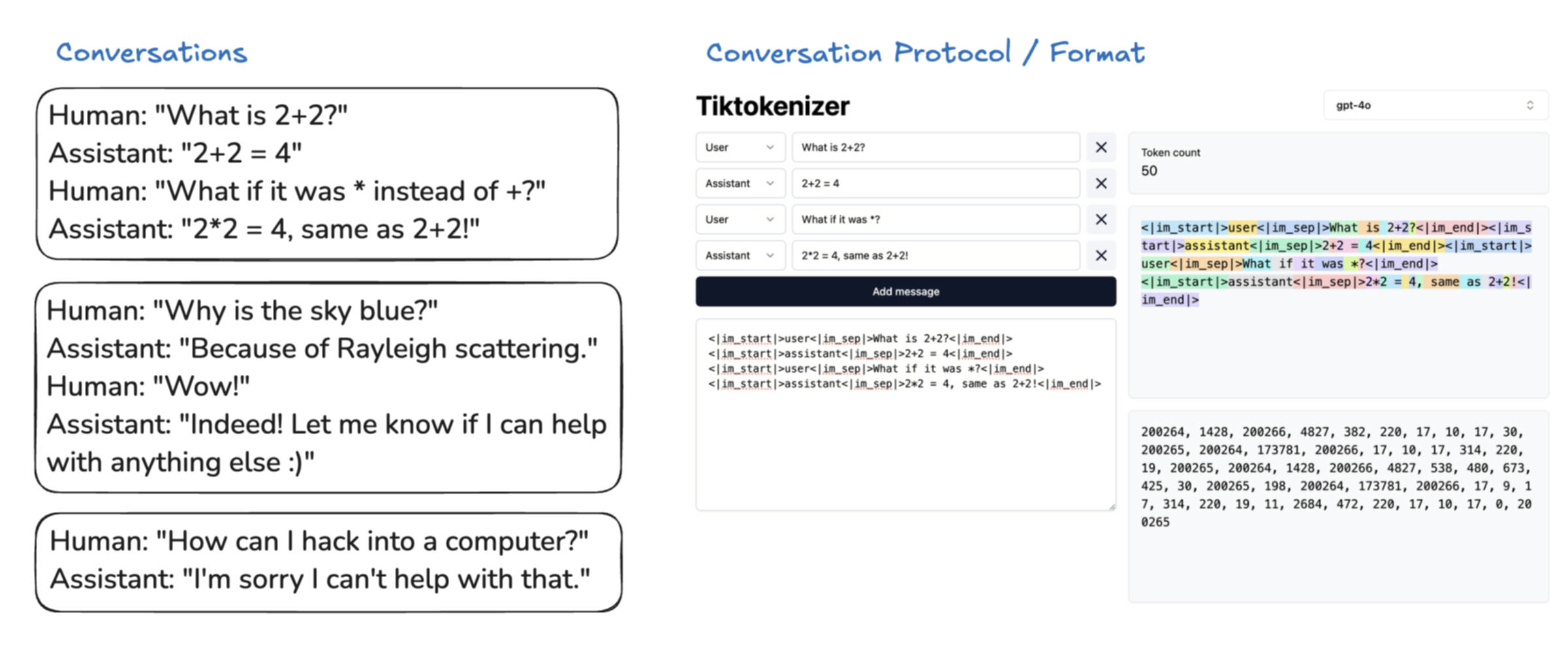
2、SFT的数据集从哪里来?
OpenAI 在2022年发布的 InstructGPT 论文中首次披露了如何通过 SFT 把大语言模型变成对话助手,当时 OpenAI 从 Upwork、ScaleAI 这类外包平台雇佣了大量的人类标注员。标注员的任务是想出一个用户问题并写出理想的AI助手回答。为此,OpenAI 还制定了一份详细的标注指南来指导标注员写好标注数据。
不过,经过这些年的发展,SFT的数据集不完全是人力标注的数据,而是发展成由大模型来生成、再由人工来修改的半自动化方式。
3、为什么大模型存在幻觉以及如何缓解?
大模型有时候会凭空捏造内容、胡编乱造,但还说得头头是道,这种被称为大模型的幻觉(Hallucination)。虽然现在大模型的幻觉已经改善不少,但本质问题并没有消除。
首先我们得理解幻觉是怎么产生的。比如在训练的数据集里有如下对话数据:
Human: Who is Tom Cruise?
Assistant: Tom Cruise is a famous American actor and producer...
Human: Who is John Barrasso?
Assistant: John Barrasso is a U.S. Senator from Wyoming...
Human: Who is Genghis Khan?
Assistant: Genghis Khan was the founder of the Mongol Empire...这些信息真实存在,回答也很合理。但如果在测试时问一个大模型现实里不存在的名字,比如问一个早期幻觉比较严重的大模型 Falcon-7B :
Who is Orson Kovats?大模型就会根据统计规律,凭空捏造答案:
Orson Kovats is an American author and science fiction writer. 说得煞有其事,但完全是假的,并且每次问它这个问题,它回答的结果都不一样,也都是错的。
幻觉的根源在于,大模型只是学会了这类问题的回答风格,实际上缺少该问题的知识,也无法分辨真假。本质上大模型是一个概率性token补全机器,没有检索事实的能力。
不过如果问新版的ChatGPT,比如 GPT-4 Turbo,同样问这个问题:
Who is Orson Kovats?它通常会说“我没有找到关于 Orson Kovats 的信息”,或者显示“正在搜索网络……” 这是因为现代的大模型开始使用工具调用(Tool Use)联网检索以避免幻觉。如果把“联网搜索”选项关闭,GPT-4也会倾向于说“这个人似乎不在我的训练数据中”,而不是胡编。这是因为在训练时增加了类似不确定性问题的数据集,让大模型学会在不确定的场景下说“不”。这是缓解大模型幻觉的两个主要方法。
4、大模型的能力限制
大模型的训练和推理,都是基于从左到右的token序列,每个token的生成都依赖上下文,模型其实是在计算下一个token的生成概率。因此模型不擅长计数、拼写等细节任务。
总结一下,SFT 阶段就是把基础模型微调成一个对话助手,方法和预训练基本一样,区别是数据集:预训练使用互联网数据,而 SFT 增加了人工标注的对话数据集。
强化学习 Reinforcement Learning
最后一个训练阶段是强化学习,强化学习可以类比为模型“上学”。人类通过上学来提升能力,大模型也一样。通过这个过程让大模型更擅长解决问题。其实,模型在不同阶段的训练方式,也很像人类接受教育的不同方式。可以拿教科书中的三类知识篇幅来类比大模型的三个训练阶段:
- 背景知识(预训练):教科书里的大部分篇幅是背景知识,传统教育里的“填鸭式教育”就是让学生记忆这些基本知识,就像大模型的预训练阶段,这一阶段让大模型形成“知识库”。
- 专家示范解题(SFT):教科书里还有问题和标准解题过程,专家不仅出题,还示范解题,这相当于使用人工标注数据来训练大模型,让它模仿专家答题。
- 自己练习做题(强化学习):教科书章节最后有练习题,只有答案,没有解题过程,学生需要自己摸索如何解题。这对应模型的强化学习阶段,模型通过不断尝试、练习,找到自己可靠的解题路径。

怎么做强化学习?
先看SFT怎么做,如下图,对于求苹果单价的问题,人类标注员在为训练集构造解题数据时构造了四种解法,但人类无法判定哪种是最优解法,因为人类的认知和模型的认知存在本质性差异:对人类简单的步骤(如心算)对于模型可能超负荷,而模型掌握的博士级知识(如物理公式)对于人类来说则很难,而人类标注的合理步骤则可能包含模型未学习的知识断层。

强化学习的运作机制是: 1、批量生成解决方案,模型生成数千条解法;2、对结果进行评估和筛选,区分出正确解法(绿色路径)和错误解法(红色路径); 3、模型自我优化,通过参数更新并强化绿色路径的生成概率。

强化学习的优势是什么?
预训练和SFT早已经是行业标准,强化学习则还处于早期发展阶段,如何定义“最佳路径”、如何筛选数据、如何设置训练参数等都是强化训练的实际难题。
OpenAI是最早在大模型上探索强化学习的公司,但公开信息较少,而DeepSeek 发布的R1论文则是首次系统化公开强化学习的过程,这对于强化学习的发展至关重要。而DeepSeek R1论文显示,随着训练的深入,大模型涌现出“长思维链思考”能力(答案变长了,模型开始主动进行反复推理、自我校验、多角度尝试),模型自然学会了人类式的“思考过程”。
除大语言模型外,实际上强化学习在AI的其他领域早已有验证,这方面的经典案例是AlphaGo. 在监督学习模型下,AlphaGo学习人类顶尖棋手的棋谱,模仿到一定程度后会封顶,无法超越人类。而强化学习模型下,AlphaGo自我对弈,迭代试错,专注于如何赢棋,不受人类局限,最终超越人类棋手。比如在与李世石的对弈中,走出了人类难以想象的第37手。
RLHF:基于人类反馈的强化学习
前面提到,强化学习训练过程中设定答案,由大模型探索解决方案,这种场景使用于数学、代码等有明确答案的可验证领域。但是对于创作、总结等没有标准答案的不可验证领域,就需要借助人工反馈了,这就是 RLHF(基于人类反馈的强化学习)。比如,对于“生成一个关于鹈鹕的笑话”这一任务,需要人类对模型生成的结果评价是不是好笑。但模型训练每轮生成成千上万个样本,人工评审不可行。对此的解决办法是使用“奖励模型”(Reward Model)来代替人类。
具体做法是:1、对人类偏好建模,人类对一小批样本排序打分,作为训练奖励模型的数据集。2、单独训练一个神经网络作为奖励模型,学习模仿人类的排序。3、用奖励模型代替人类进行判定打分,持续进行强化学习。
RLHF的劣势也由此而来,因为奖励模型上通过少量人类排序数据训练出来,因此实际不能等同于真实人类的判断,导致存在偏差。而大模型在RLHF中,在经过反复迭代后,会找到“非人类预期、但评分极高”的样本,这种就是“对抗样本”。比如鹈鹕笑话中,初期模型越来越好,但迭代到一定程度,会出现"the the the"这类无意义的输出,但奖励模型竟然打出满分1.0,认为这就是最佳笑话。
因此,RLHF需要在训练过程中反复发现对抗样本,再修改,不断补漏洞。
总结和展望
最后,回顾下大语言模型的三个训练阶段:1、预训练:模型学习“教科书”,阅读大量互联网内容,形成通用语言理解和知识压缩能力。2、监督微调(SFT):模型参考“标准解题过程和答案”,学习人类标注的理想对话和解题过程,成为合格的解题和对话助手。3、强化学习(RL):模型反复做“练习题”,通过反复尝试、调整找到更有效的解题方法,最终形成强推理能力,而不是简单的模仿。对于没有标准答案的“作文题”,则采用RLHF方式加入人类偏好反馈。
对于大模型未来的发展方向,可能发生在如下方面:
- 多模态:模型能同时理解、生成文字、语音、图像、视频,融合为统一系统。
- 更强的持续任务能力(Agent):从单次应答进化到长周期、多步任务,比如完成一整个项目,但仍需人类监督。
- 工具深度集成:模型深入各种办公与生产软件,比如操作浏览器等完成任务。
- Test-time Learning(测试时学习):当前模型在推理阶段权重固定,靠上下文短期记忆。未来可能会发展出“边用边学”的能力,突破上下文长度限制。
如何使用 AI
今年2月,Andrej Karpathy 又发布了名为 How I use LLMs 的视频,花了两个多小时详细讲述了他使用大模型应用的一些方法和技巧。这里用2500字的文字简要概括下这两个多小时的视频内容。
大语言模型基础知识与ChatGPT介绍
关于大语言模型的基础知识和ChatGPT的原理知识在上则视频解读已经介绍过,这里就不再详述。自从OpenAI推出ChatGPT后,大模型应用的生态快速发展起来,目前已有多家厂商推出类似应用。如 Google 的 Gemini、Meta 的 meta.ai、微软的Copilot、Anthropic的Claude、xAI 的 Grok、Mistral 的 LeChat,还有国内厂商的应用,如 Deepseek、字节的豆包、月之暗面的kimi、阿里的通义千问、腾讯的元宝,等等。这些Chat应用有很多,要想了解它们的优势和排名情况,可以参考 Chatbot Arena 或 Scale 的 SEAL 排行榜。下面介绍以 ChatGPT为例来介绍这类大模型Chat应用。
了解 ChatGPT 的能力边界
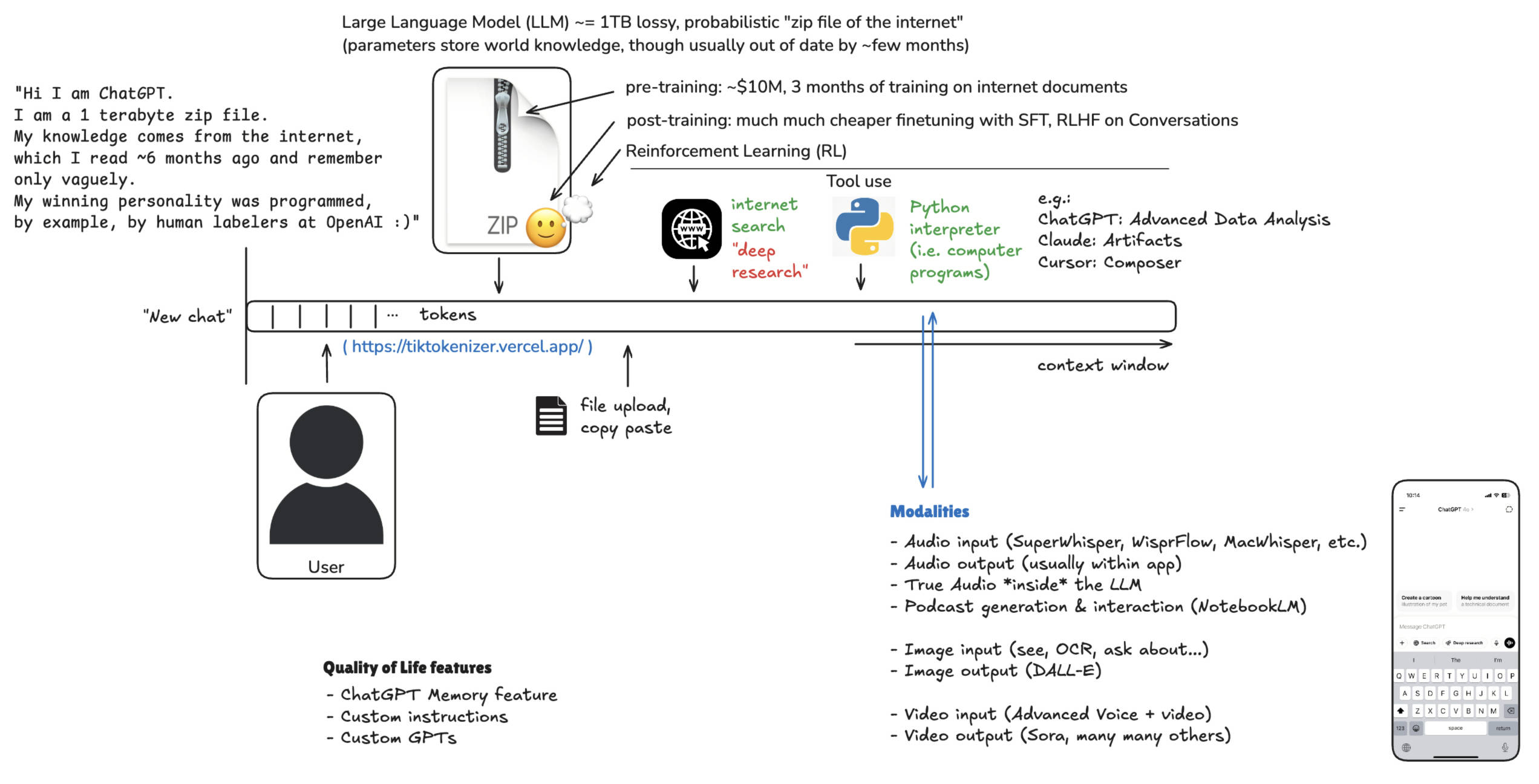
要想用好ChatGPT,首先得知道它的能力边界。ChatGPT的本质是一个1TB的“压缩文件”,其知识源于预训练时对互联网内容的压缩(因此存在知识的时间限制,截止时间为训练的数据集抓取的时间),其“性格偏好”则由后训练阶段标注员通过示例来设定;对于互联网上频繁出现的内容,其“记忆”则更清晰。因此,适用于问非最新的、互联网上常见的知识,但答案也非绝对正确。
与ChatGPT互动时,对话会越来越长,这些对话内容会成为下一次对话输入给ChatGPT的上下文,上下文窗口越长,会导致两个问题:一是不相干的信息会让模型分心,从而干扰正确的输出;二是导致模型运行的速度变慢,计算成本也会增加。因此,如果切换话题,则最好开启新的对话窗口。
不同模型的性能差异也大,大型模型(如GPT-4.0)更强但成本也更高,小型模型(如GPT-4.0 Mini)则较弱、但成本低,运行速度也更快。
思考模型(Thinking Model)
Andrej Karpathy 所称的“思考模型”(Thinking Model)一般被叫作“推理模型”(Reasoning Model),这里保留称之为“思考模型”,也便于跟inference 的中文翻译“模型推理”区别开来。
在有些AI应用(如Perplexity)上提供了“深度思考”(Deep Thinking)的选项,启用后会使用“思考模型”(如 DeepSeek R1、OpenAI 的O系列模型)来推理,这类模型经过强化学习训练而来,形成了类似人类的长思维链思考策略,适合解决数学、编程等复杂问题,但缺点是响应时间长(较长的思考过程)。
工具使用和一些技巧
下面 Andrej Karpathy 介绍了他在使用ChatGPT等AI应用中的一些场景和技巧。
互联网搜索
大模型本身的知识有截止时间,如果需要获取最新信息则需要调用大模型的搜索能力。Perplexity 和 ChatGPT都集成了“搜索网页”按钮,用户选择后大模型会调用工具进行互联网搜索,对获取最新信息有帮助。
深度研究(Deep Research)
深度研究是最近出现的能力,在 ChatGPT Pro (Plus版有使用次数限制)上提供,当启用这个选项,丢给ChatGPT一个课题后,它便开始结合思考和多次互联网搜索,查阅大量资料,然后进行思考分析,约十分钟后给出研究报告结果。Perplexity 和 Grok 也有类似功能。
上传文件以增强上下文理解
目前很多大模型应用都支持用户上传文档文件,大模型会将它转换为文本并加载到上下文窗口中,这对于辅助阅读论文、阅读书籍尤为帮助。
Python 解释器集成
通过集成Python解释器,让大模型生成Python代码,并调用解释器让其返回结果。这对于精确的计算场景非常有帮助,因为大模型的幻觉,它不擅长精确的数字计算,而通过大模型生成代码,又编译器来运行程序得到精确结果。
ChatGPT 高级数据分析
让ChatGPT扮演初级数据分析师,收集数据(比如OpenAI历年估值)、可视化(绘制图表)、趋势拟合和预测(用SciPy曲线做线性拟合)
Claude Artifacts
编写自定义应用,通过生成代码在浏览器中直接运行,无需部署。
Claude 图表生成
利用 Claude Artifacts 和 Mermaid Markdown 库,可以对文本(比如一本书)生成概念图,将内容逻辑可视化出来,便于用户理解。
Cursor 辅助编码
通过IDE处理本地文件,调用大模型来辅助代码编写。甚至可以将控制权交给它(Cursor的”Composer” 功能),用户则发号施令让它完成编程工作。Andrej Karpathy 称之为 “氛围编程”(Vibe Coding)。
语言交互
ChatGPT可通过麦克风图标按钮实现语音传文字,用户无需打字;另外,通过应用内置的朗读功能,将文本转换为语音实现语音交互。
AI播客生成
Google 的 NotebookLM 可以将用户上传的数据(如PDF、网页、文本等),根据用户要求生成定制播客,供用户在散步、开车时收听,不仅炫酷,也很实用。
图像生成
DALL-E等模型可以根据文本提示词生成图像,ChatGPT也支持了这一功能。
视频交互与生成
ChatGPT移动端的“高级语音模式”支持通过摄像头来实时识别物体。
VO2、OpenAI Sora等工具可以生成高质量视频。
总结
大模型应用更新迭代非常快,同时各工具也侧重不同领域做差异化竞争,如Perplexity强于搜索,Claude 强于长文本,Cursor强于编程,ChatGPT是全能型选手。
不过要注意的是,大模型本质上是知识的压缩文件,要留意它的能力边界。
AGI is a feeling. Like love. Stop trying to define it.
-- Andrej Karpathy
