周刊第19期: 一起学习 MCP
模型上下文协议的起源、原理与发展生态
本文为周刊第19期,前期周刊参见:周刊系列。
最近学习了 MCP (Model Context Protocol, 模型上下文协议)相关的文档、书籍和文章,借此在本期周刊中对其进行梳理与总结。本文将围绕 MCP 的由来与所解决的问题、核心概念与运行机制,以及其生态与发展现状展开,帮助大家快速理解 MCP 的全貌。
受万维钢的启发,从本篇周刊开始,我会计算每篇文章的“思维密集度”,也就是花在写文章的时间(包括前期相关资料收集、学习的时间),除以阅读文章所需的时间,所得到的值。本文的思维密集度 = 约30小时(前期学习花费时间)+ 11小时(总结及写作时长)÷ 18分钟(阅读本文时长)≈ 137.
本文思维密集度 = 137
1. MCP 的起源
OpenAI发布ChatGPT让人们看到了大语言模型(LLM)的强大能力,而ChatGPT也在短时间内成为了超级互联网应用,甚至改变了人们寻找知识的习惯,很多人在互联网上搜索信息不再优先使用搜索引擎,而是从ChatGPT等AI对话类应用获取信息。
但大模型也有一个弱点,那就是它是通过历史数据训练而成,其知识在训练时就已经固定,无法获取训练之后的新信息。正如Anthropic在推出MCP的介绍文章中说的那样:“即便是最先进的模型,也受限于与数据隔绝——被困在信息孤岛和遗留系统之后。”为了解决这一问题,行业采用了两个解决方案。第一个解决方案是模型微调,也就是在基础大模型上加入一些新的数据集进行增量训练,这种场景仍需要进行训练后再部署,一则成本比较高,二则是实时性比较高的场景也不能满足。而另一个解决方案就是补充上下文,在推理时为模型注入外部知识作为输入上下文,让模型基于最新资料进行回答,从而弥补大模型原有知识的不足。
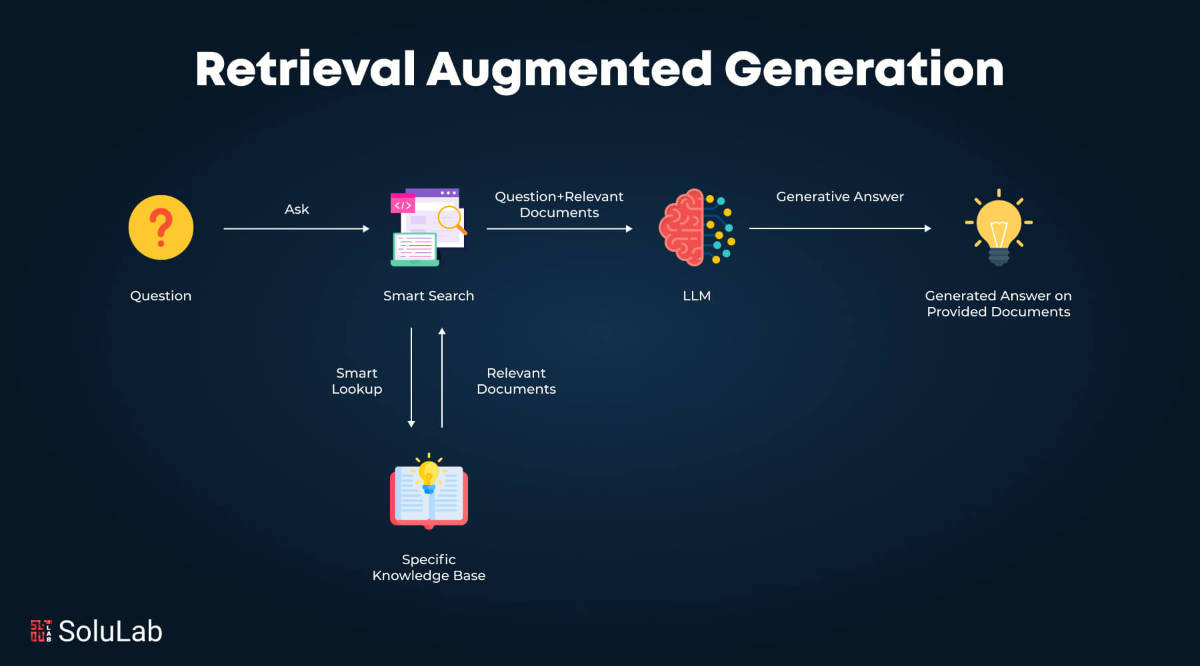
为大模型补充上下文的方案有很多,比如我们在与ChatGPT等AI应用对话时,大模型能结合之前对话的上下文来回答,这是因为AI应用将对话内容进行了存储记录,压缩处理成后续问答的上下文给到大模型。这种方法受限于用户的对话内容,若想要获得更广泛且可更新的上下文,通常会采用RAG等技术路线.

RAG(Retrival Augmented Generation, 检索增强生成)是一种让大模型结合外部知识库的方法,RAG 所代表的三个缩写词就是它的工作原理:Retrival(检索):首先,当用户发出提问时,AI应用将问题通过向量化检索的方式获得与问题相关的文档知识;Augmented(增强):然后,AI应用把检索到的资料拼接到Prompt中,作为增强上下文;Generation(生成):最后,模型基于问题+外部资料信息生成答案。RAG的优势在于不需要训练模型,能够接入最新的知识,并保持知识库的更新。但其限制在于,RAG依赖于检索到信息的质量,同时还要求检索过程足够高效,但实际应用中,检索速度和检索准确率是比较大的技术挑战。另外,RAG通常使用向量检索(也可与关键词/混合检索组合)并维护可更新的检索索引,而当知识库规模化后,其成本、性能、检索精度都可能成为瓶颈。
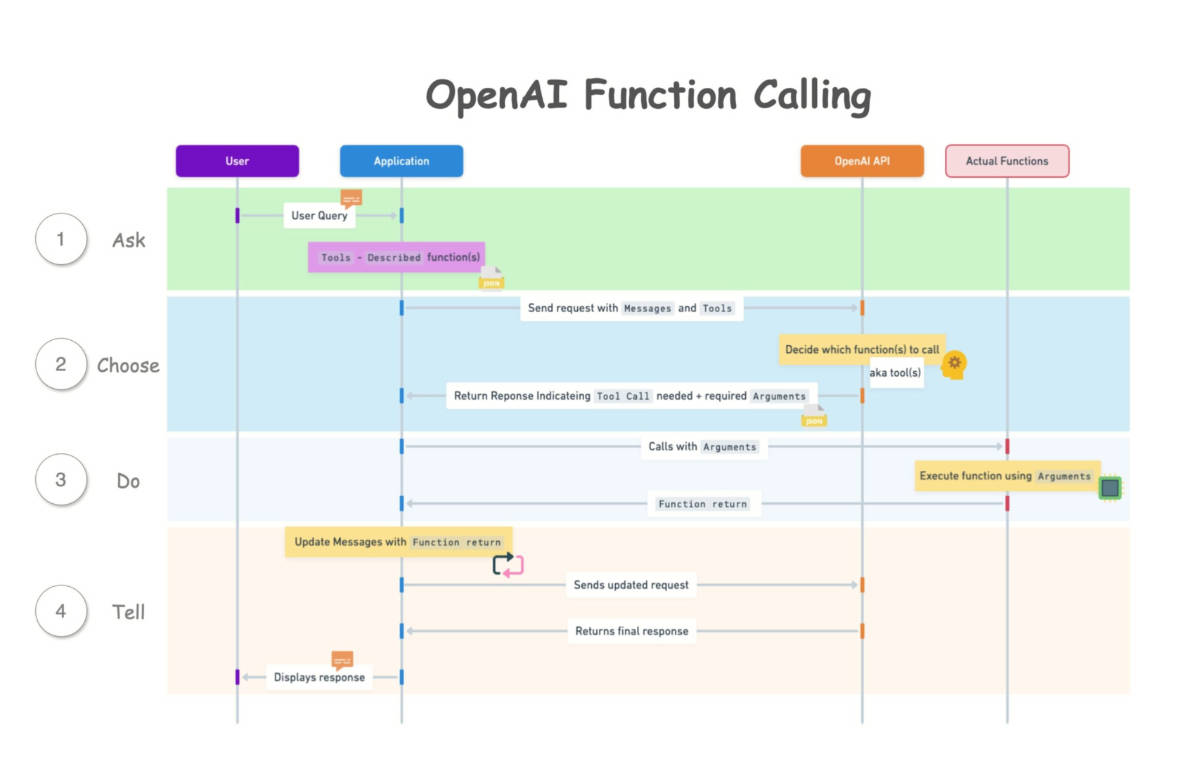
2023年6月OpenAI在其模型API中更新发布了函数调用(function calling)能力,它允许大模型将自然语言请求转换为函数调用,让AI应用可以调用外部工具。其工作原理是:第一步,AI应用开发者定义函数列表,包括名称、用途、参数类型。第二步,用户发出问题,AI应用将函数列表作为上下文发送给大模型。第三步,大模型根据用户输入判断需要调用的函数,生成调用参数。第四步,AI应用执行该函数并将结果发送给大模型,作为补充上下文信息供大模型生成最终的答案。这一特性也极大扩展了大模型的能力边界,通过函数调用的方式,大模型能够外挂各种外部数据源,同时还能执行各种类型的操作。
在OpenAI推出函数调用机制后,各大模型厂商纷纷跟进,分别都支持了函数调用机制。但随之而来也存在一些问题,因为函数调用是一种机制,而非标准,虽然函数定义都是JSON格式,但个大模型厂商实现方式不同,结构差异很大;另外,需要开发者为每种模型或AI应用编写特定的适配代码。这些都是函数调用机制在实际应用场景中迫切需要解决的问题。
不过,OpenAI在推出函数调用机制后,没有更进一步统一行业标准,而是着急推出GPTs的生态战略。OpenAI在推出函数调用后的同年11月,也就是2023年开发者大会上,推出了GPTs, 这是专为特定任务创建的ChatGPT 的定制版本,用户可以打造自己的GPTs, OpenAI CEO 山姆·奥特曼还特意演示了如何在几分钟内创建一个商业顾问GPTs。到次年2024年1月,OpenAI开放GPTs Store, 上线不久,商店内的GPTs就达到了300万。但巨大的数量并没有产生实质性的效果,有报道称,95%的GPTs应用的用户数不超过100人,绝大多数GPTs的用户只有一、二人。这也暴露了GPTs的问题,GPTs想法的初衷是好的,普通用户通过简单的操作比如调整提示词便可以创建专属的AI应用,但这种低门槛也就意味着大量低质量的应用被快速构建出来,实际上没有什么用处。在实际的工作和生活场景,AI应用需要与各种IT工具交互才能产生真正的价值。
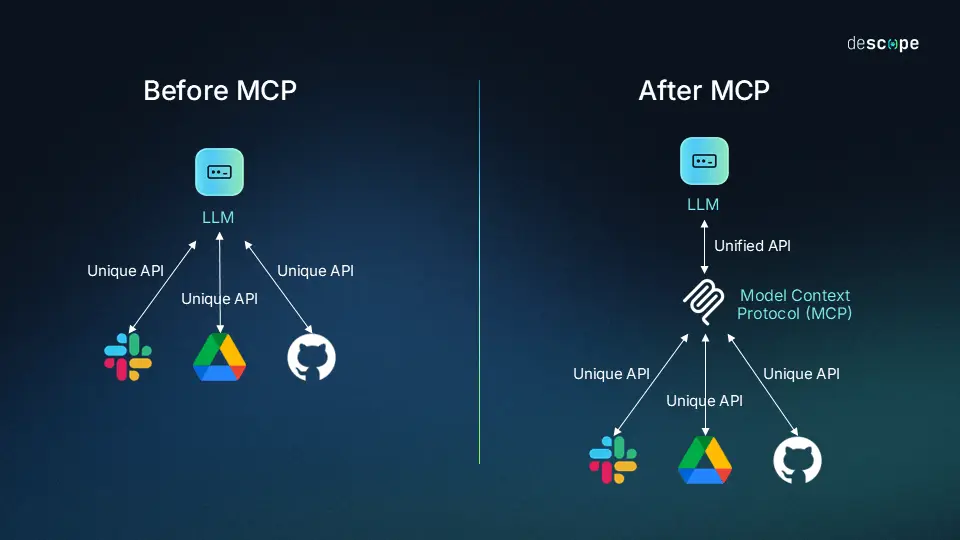
OpenAI所忽视的标准被Anthropic搞出来了。2024年11月,Anthropic推出MCP,即模型上下文协议(Model Context Protocol),这是一个开放标准,用一个统一标准的协议,让大模型应用可以安全、方便地访问外部数据并进行工具连接。可以认为,MCP是在函数调用基础上做的升级和抽象。
2. MCP 的基本概念
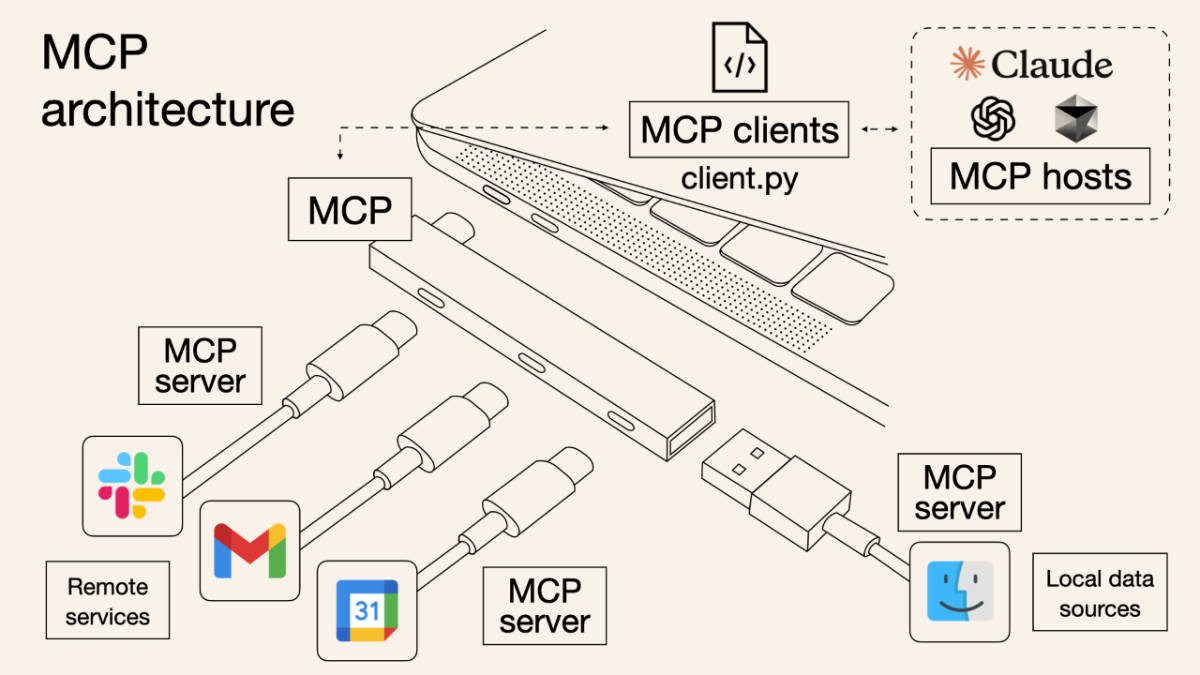
MCP 在架构上有三个角色:主机(MCP Host)、客户端(MCP Client)、服务器(MCP Server),它们通过 MCP 协议进行协作。MCP 主机一般是AI应用,如ChatGPT等AI对话应用,或智能体Agent,或如Cursor等AI IDE等。MCP 服务器则是负责对接外部数据或工具服务,通过MCP标准数据格式将内容发送给MCP客户端。MCP 客户端则是MCP主机与MCP服务器连接的桥梁,它附属于主机上,由主机任务创建并调度,从而实现AI应用与外部数据或工具服务的交互。
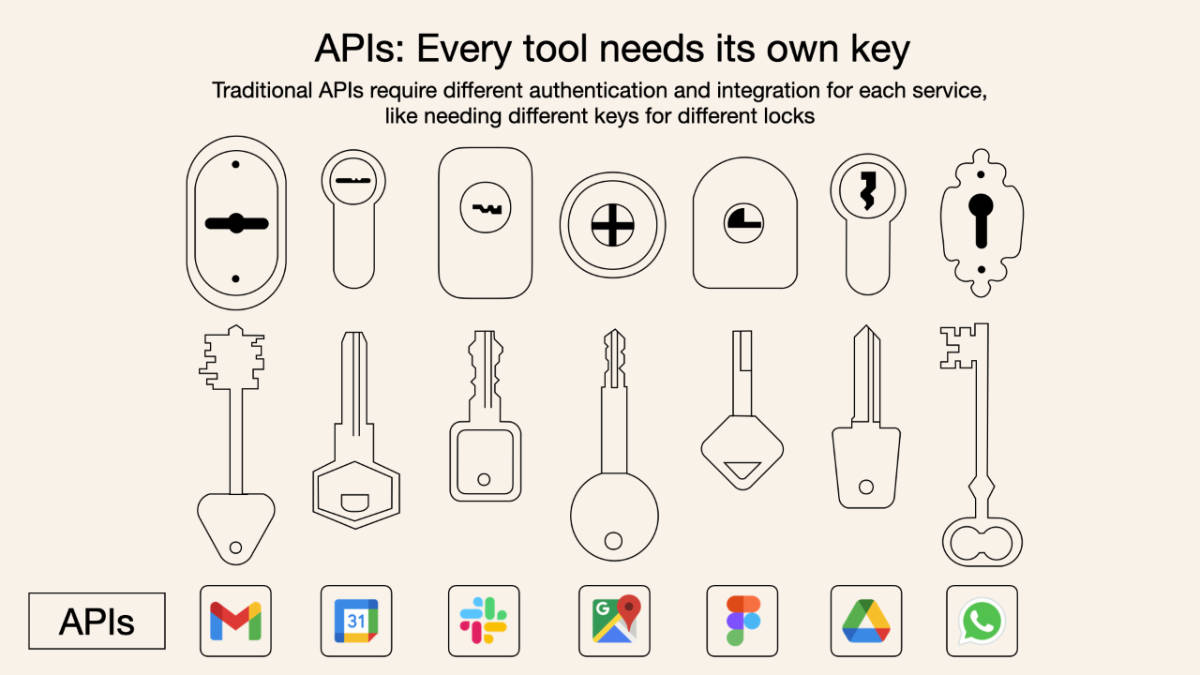
对于MCP的这些概念,网上有张图非常形象的解释了它们的关系。MCP就像是电脑的拓展坞,有了它之后,无论是远程调用的服务(如数据库、Web服务、远程系统)还是本地服务(文件系统、本地工具)都可以被主机(AI应用)所调用。
相比之下,前面提到的函数调用或其他API调用方式就需要AI应用做定制的适配。
MCP官方文档中对MCP架构描述如下。MCP客户端与MCP服务器一对一连接。
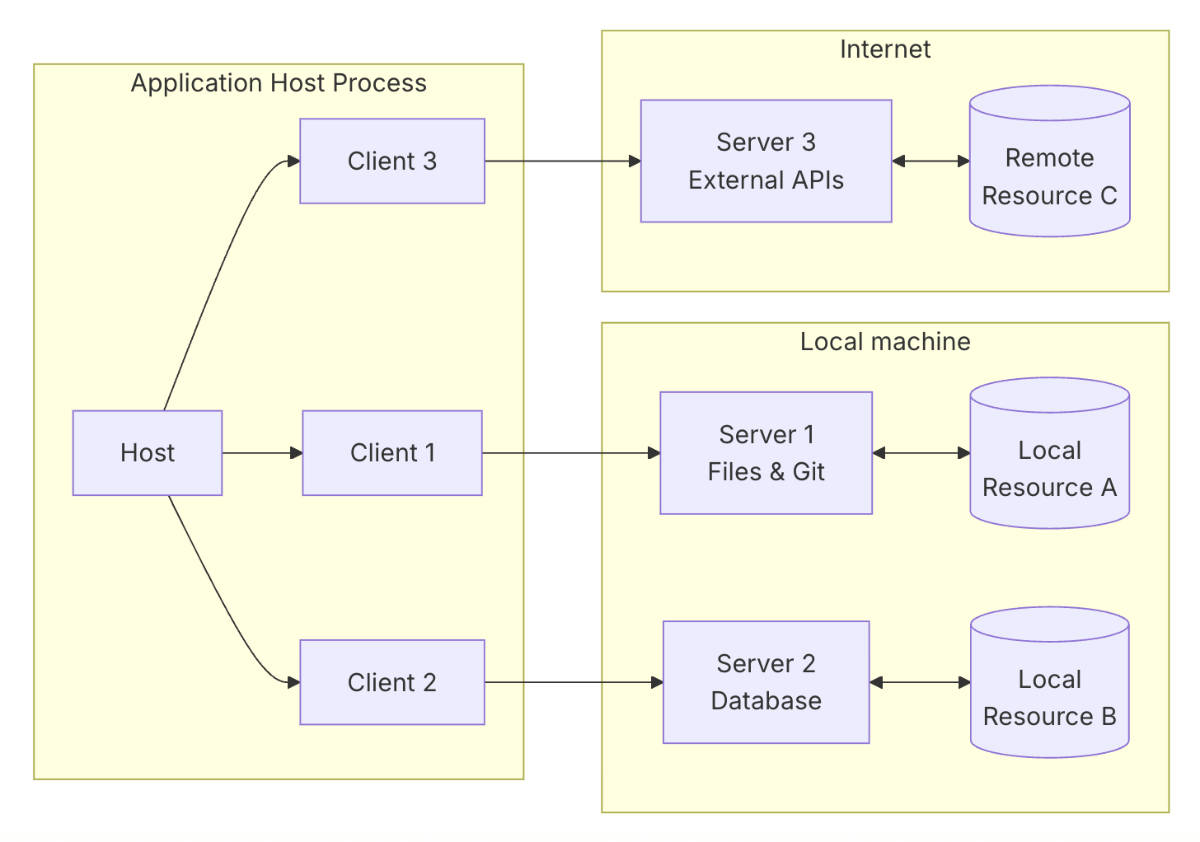
MCP协议包含两层:数据层和传输层。数据层定义了基于 JSON-RPC 的“客户端-服务器”通信协议,包括生命周期管理、核心原语(tools, resources, prompts)、通知机制。传输层定义了通信机制与通道,包括连接建立、消息封装、认证等。MCP支持两种传输机制。一种是对本地数据服务的STDIO 传输,通过标准输入/输出流在同一台机器上的本地进程间通信,没有网络开销。另一种是对远程数据服务的流式 HTTP 传输。
数据层方面,由于MCP是有状态协议,因此需要生命周期管理,以便于协商客户端与服务器所支持的能力。协议支持实时通知,以实现服务器与客户端之间的动态更新。例如,当服务器的可用工具发生变化(新增、修改、下线)时,服务器可以发送工具更新通知,告知已连接的客户端这些变化。
原语 Primitives
MCP协议最重要的概念是原语,原语定义了客户端和服务器能够互相提供的内容,规定了可以与 AI 应用共享哪些上下文信息,以及可以执行哪些范围内的操作。
MCP服务器有三个核心原语:
- 工具(Tools):可执行的函数,AI 应用可以调用它们执行操作(例如文件操作、API 调用、数据库查询)。
- 资源(Resources):为 AI 应用提供上下文信息的数据源(例如文件内容、数据库记录、API 响应)。
- 提示词(Prompts):可复用的模版,用于组织与大语言模型的交互(例如系统提示词、少样本示例提示词等)。
每种原语都包含相关联的方法用于发现(*/list)和获取(*/get),比如用于工具发现的(tools/list),还有一些方法适用于特定原语,比如工具调用(tools/call)。MCP 客户端则使用 */list 方法来发现所有可用原语。
比如我们实现一个图书管管理的MCP服务器,在工具里可以定义一个借阅图书的工具:
{
"name": "borrowBook",
"description": "Borrow a book from the library",
"inputSchema": {
"type": "object",
"properties": {
"userId": { "type": "string", "description": "Library user ID" },
"bookId": { "type": "string", "description": "Unique book identifier" },
"dueDate": { "type": "string", "format": "date", "description": "Return due date (YYYY-MM-DD)" }
},
"required": ["userId", "bookId", "dueDate"]
}
}而AI应用里就可以使用该工具来借阅图书:
borrowBook(userId: "007", bookId: "101", dueDate: "2024-06-15")MCP客户端也定义了三个核心原语:
- 采样(Sampling):让服务器无需集成或对接大模型,而是允许服务器请求客户端(已拥有模型访问能力)代表其处理任务。这样客户端就能完全掌控用户权限与安全措施。
- 根目录(Roots):根目录定义了文件系统的边界,允许客户端告知服务器其操作范围,以便保持安全边界。
- 引导(Elicitation):使服务器能在交互过程中向用户请求特定信息,从而构建更动态、更灵活的工作流。
除了这三个核心原语,MCP客户端还可以定义如日志(Logging, 允许服务器向客户端发送日志消息,用于调试与监控)等原语。
MCP运作过程示例
下面以一个MCP “客户端-服务器”的交互示例来解释MCP的运作过程。
1) 初始化 (生命周期管理)
MCP 交互从生命周期管理的能力交互握手开始,首先是客户端发送 initialize 请求来建立连接并协商支持的能力。
{
"jsonrpc": "2.0",
"id": 1,
"method": "initialize",
"params": {
"protocolVersion": "2025-09-08",
"capabilities": {
"elicitation": {}
},
"clientInfo": {
"name": "client-example",
"version": "1.0.0"
}
}
}而服务器也会回应:
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"protocolVersion": "2025-09-10",
"capabilities": {
"tools": {
"listChanged": true
},
"resources": {}
},
"serverInfo": {
"name": "server-example",
"version": "1.0.0"
}
}
}capabilities 里包含着双方声明的原语,即暴露的能力。在这个例子中,客户端声明了 elicitation 原语,表明服务器可以处理用户交互请求,而服务器声明支持 tools 和 resources 原语,而 tools/list_changed 则说明当工具列表更改时,服务器会发送消息通知。
初始化成功后,客户端会发送通知表明已准备就绪:
{
"jsonrpc": "2.0",
"method": "notifications/initialized"
}在初始化阶段,AI应用会建立通过客户端管理建立与各服务器的连接并存储它们的能力信息以决定后续调用哪些服务器的功能。
2) 工具发现(原语)
连接一旦建立,客户端就可以发送 tools/list 请求发现服务器提供的工具。
{
"jsonrpc": "2.0",
"id": 2,
"method": "tools/list"
}服务器回复:
{
"jsonrpc": "2.0",
"id": 2,
"result": {
"tools": [
{
"name": "checkBookAvailability",
"title": "Check Book Availability",
"description": "Check if a specific book is available in the library",
"inputSchema": {
"type": "object",
"properties": {
"bookId": {
"type": "string",
"description": "Unique identifier of the book"
}
},
"required": ["bookId"]
}
},
{
"name": "borrowBook",
"title": "Borrow Book",
"description": "Borrow a book from the library system",
"inputSchema": {
"type": "object",
"properties": {
"userId": {
"type": "string",
"description": "Library user ID"
},
"bookId": {
"type": "string",
"description": "Unique identifier of the book"
},
"dueDate": {
"type": "string",
"format": "date",
"description": "Return due date (YYYY-MM-DD)"
}
},
"required": ["userId", "bookId", "dueDate"]
}
}
]
}
}服务器的响应包含一个tools数组,里面是各工具的元数据信息,包括每个工具在该服务器内的唯一标识符 name, 名称 title, 描述 description, 以及输入参数的 JSON Schema 定义 inputSchema.
AI 应用会将所有 MCP 服务器提供的工具合并成统一的工具注册表,供大模型获取并准备后续调用。
3) 工具调用(原语)
获得工具信息后,客户端可以通过 tools/call 方法调用工具。
{
"jsonrpc": "2.0",
"id": 3,
"method": "tools/call",
"params": {
"name": "borrowBook",
"arguments": {
"userId": "U12345",
"bookId": "B56789",
"dueDate": "2025-09-30"
}
}
}相应地,服务器在执行工具成功后会反馈工具调用结果。
{
"jsonrpc": "2.0",
"id": 3,
"result": {
"content": [
{
"type": "text",
"text": "Book 'Introduction to AI' has been successfully borrowed by user U12345. Due date: 2025-09-30."
}
]
}
}当大模型在对话中决定要调用工具,AI应用会拦截工具调用,将请求路由到对应的MCP 服务器,执行工具调用,并将结果返回给大模型,这样大模型就能够访问到外部的实时数据。
4) 实时更新(通知)
MCP 支持实时更新,允许服务器主动告知客户端变化,而不是等待客户端请求。
比如当服务器工具发生变化,服务器可以发送通知给客户端:
{
"jsonrpc": "2.0",
"method": "notifications/tools/list_changed"
}通知消息无需响应。不过客户端在收到工具变化通知后,一般会立刻向服务器发送请求获取工具列表。
3. MCP 的生态
MCP自发布以来,便受到了众多开发者的关注,也有很多开发者参与社区。各AI应用厂商和各大模型厂商也纷纷跟进,逐渐成为行业的事实标准,也因此形成了丰富的生态,从配套工具到解决方案,从市场到周边。这里也列举一些。
配套工具
MCP官方提供了TypeScript、Python等多种语言的SDK,另外还提供了调试工具和命令行工具,通过这些配套工具可以很方便的开发MCP服务器和客户端。我根据《这就是MCP》的指导也很快开发了flomo的MCP服务器,代码在 hutusi/flomo-mcp, 这里就不展开描述。
MCP应用市场
MCP官方没有推出MCP应用市场(2025/09/09 update: MCP官方于本文发表8小时后宣布官方MCP Registry, 也就是MCP应用市场),只是在GitHub上用一个README收集了MCP服务器清单,不过有很多第三方的MCP市场,如 smithery.ai, MCP.so, MCPMarket.com, modelscope.cn/mcp 等。其中 mcp.so 可能是目前MCP服务器收录最多的应用市场,它来自于一位网名为艾逗笔的技术极客之手。艾逗笔从腾讯离职后做独立开发,去年11月底Anthropic发布MCP,他认真阅读官方文档后突发奇想,觉得可以建一个MCP的导航站,于是立马上手,花了两个小时就把 mcp.so 开发上线了。不得不说,在AI时代有想法又能够动手的技术极客,他们的生产效率是惊人的。
MCP应用市场解决了MCP服务器收集、分类、发现的问题,在MCP生态中就像是手机应用市场。
企业级MCP解决方案
不过,我觉得MCP官方没有推出应用市场的原因,除了试图保持中立外,还可能是互联网开放的MCP应用市场内容运营和治理很难做,官方市场很难保证用户上传的MCP服务器不存在安全风险和质量隐患。(2025/09/09 update: 被打脸了,详见上段更新备注,从博客得知官方在今年三月就有这个想法。)而MCP更具有商业价值的场景是在企业内部,MCP可以帮助企业内部的AI应用在实际作业中产生效果。因此,有不少企业在探索企业级的MCP解决方案,其中比较有代表性的是阿里云的Higress+Nacos方案。
Higress是阿里云开源的云原生API网关,基于 Envoy+Istio 的架构演进而来,最初用于阿里内部的流量网关场景。在MCP场景下,Higress被用作为统一网关,让外部的AI应用调用时只接入一个网关,内部的MCP服务器的地址和安全策略都隐藏在背后。而 Nacos 是阿里云开源的服务发现与配置管理平台,在MCP场景下,就可以作为MCP服务器的注册中心。各业务系统将MCP服务器注册到Nacos上,由Higress自动发现并路由;当业务系统的MCP服务器地址变更或变更时,Nacos自动更新,而外部AI应用调用则无感知。类似下面这样的架构:
外部 AI 应用
│
▼
[Higress 网关] ← 鉴权、限流、审计
│
▼
[服务发现:Nacos]
│
▼
[内部 MCP Server 群]
├── 文档库 Server
├── ERP Server
├── CRM Server
└── Git Server
MCP 和 A2A
除了MCP外,AI应用互操作协议还有A2A (Agent-to-Agent Protocol)、ACP (Agent Communication Protocol)、ANP (Agent Network Protocol)等,这里主要谈一下A2A协议。
A2A协议由Google在2025年4月发布,该协议主要的目的是提供一种标准化的协议支持Agent之间协作与通信,也就是说,A2A适用于多Agent场景。在A2A协议中,规定Agent需要公开一个Agent Card,以JSON格式描述,包含它的能力、模态和限制条件等。
不过,A2A并不是取代MCP,它们之间也不是互斥的,二者可以形成互补,两者的关系如下图所示。
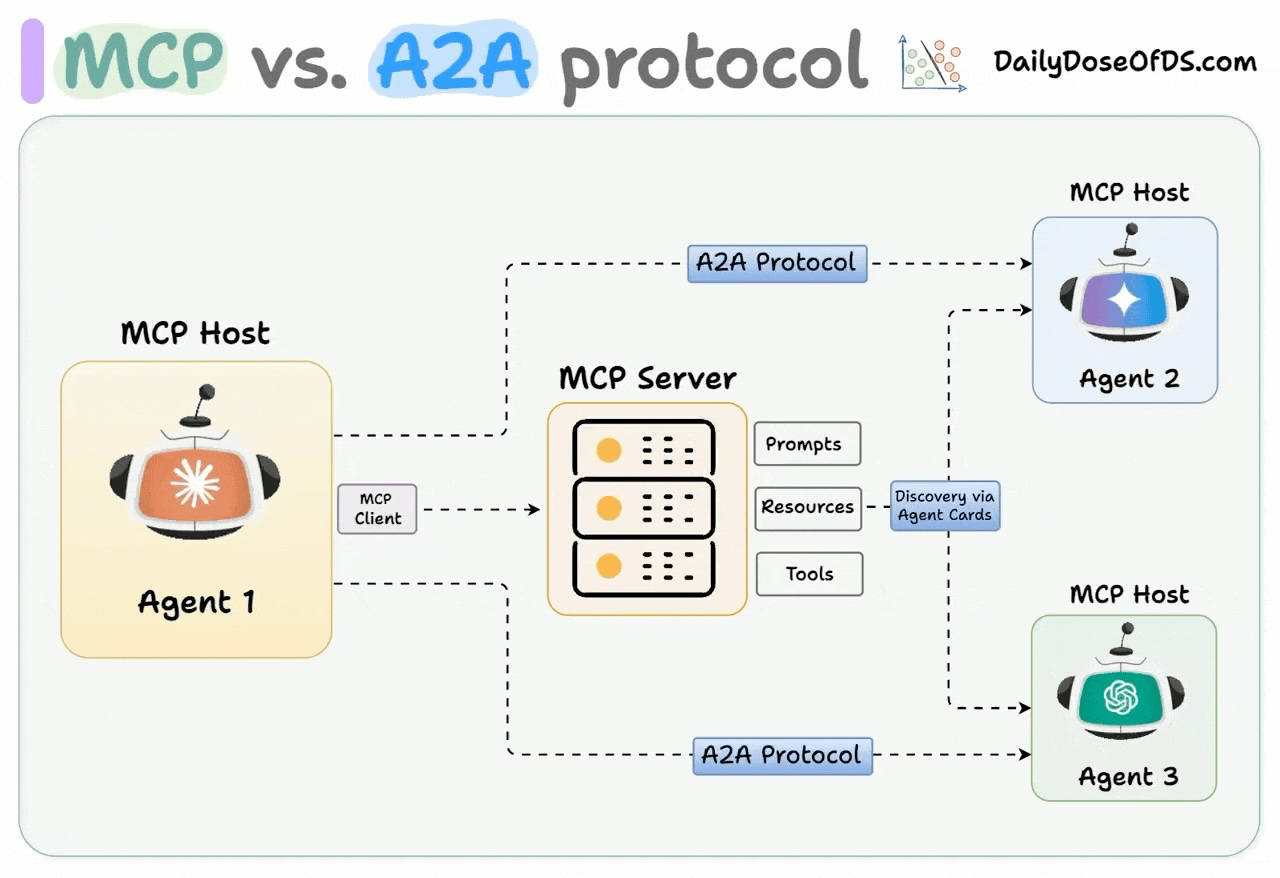
最后总结一下,MCP 如其名 (Model Context Protocol), 是为增强模型上下文而生的。通过 MCP 协议定义了 AI 应用与外部工具间的交互通用标准,使得大模型能够通过 MCP 调用工具来获取外部实时信息并执行任务,极大地扩展了大模型应用的能力。MCP 本身及生态都在不断地发展和完善,其在企业的 AI 解决方案中扮演的角色也将越来越重要。
4. 参考
Introducing the Model Context Protocol, Anthropic, 2024/11
MCP Architecture overview, modelcontextprotocol.io
OpenAI Function calling guides, OpenAI
Announcing the Agent2Agent Protocol (A2A), Google, 2025/04
What is Model Context Protocol (MCP)? How it simplifies AI integrations compared to APIs, Norah Sakal, 2025/03
《这就是MCP》 艾逗笔(著) 人民邮电出版社 2025/08
《基于 MCP 实现 AI 应用架构新范式的一线实践》 计缘(阿里云) 2025/04
昔日我曾如此苍老,如今才是风华正茂。
I was so much older then,I'm younger than that now.
-- Bob Dylan, My Back Pages
