好奇心周刊第21期: 推理模型的构建与未来
跟着 Sebastian Raschka 博客学习推理模型
本文为好奇心周刊第21期,全部周刊参见:周刊系列。
前不久,我在北京参加了ML-Summit 2025技术大会,其中有个议题是《推理模型的历史、现在与未来》,演讲者是 OpenAI 的研究科学家 Lukasz Kaiser, 他曾在 Google 工作,是 Transformer 发明人之一,也是《Attention is All You Need》论文的作者之一。他在 OpenAI 主要负责推理模型(Reasoning Models)的研究,是 OpenAI o1 的早期研究开创者。Lukasz 在这次演讲中回顾了 Transformer 的发展历史及当前的推理模型,并推测推理模型可能的未来。听这篇演讲之余,我同时也学习了 Sebastian Raschka 的博客文章 Understanding Reasoning LLMs(《深入理解推理模型》),整理本期周刊,一起了解下什么是推理模型,以及如何构建推理模型。
一、什么是推理模型
推理模型是大语言模型的一种,相对于普通的对话模型,它能够进行多步逻辑推理、中间步骤思考、以及自我验证。有些数学、逻辑、代码等类型的问题需要用到推理能力。比如,像“若一列火车以每小时60英里行驶3小时,它行驶了多远?”这样的题目就需要一定的简单推理。在 OpenAI o1出来之前的大语言模型也能回答这类问题,但答案会比较简单,OpenAI o1、DeepSeek R1 等推理模型能够用推理过程来回答问题。这种推理中间步骤有些模型会显示在答案中,将详细的推理步骤给出。像 DeepSeek 则会将这些中间思考过程呈现在思考过程区域显示给用户,与答案区别开来。而 ChatGPT 则干脆不显示,只显示模型正在思考,可能需要花费一些时间。
在《周刊第16期: Andrej Karpathy 讲 AI》这一期周刊里介绍了 LLM 的训练过程。预训练阶段训练出来的是基础模型,用户场景不能直接使用,需要进行 SFT 后训练成对话模型(如 ChatGPT 的 instruct 模型)。而推理模型则需要进行更进一步的专业化训练阶段,或者称为领域定制化(specialization). 在这个阶段,将面向特定领域场景对 LLM 进行更精细化的调整。而推理模型则是让 LLM 在中间推理步骤的复杂任务中表现出色,以应对数学、编程等复杂推理任务挑战。如下图示。
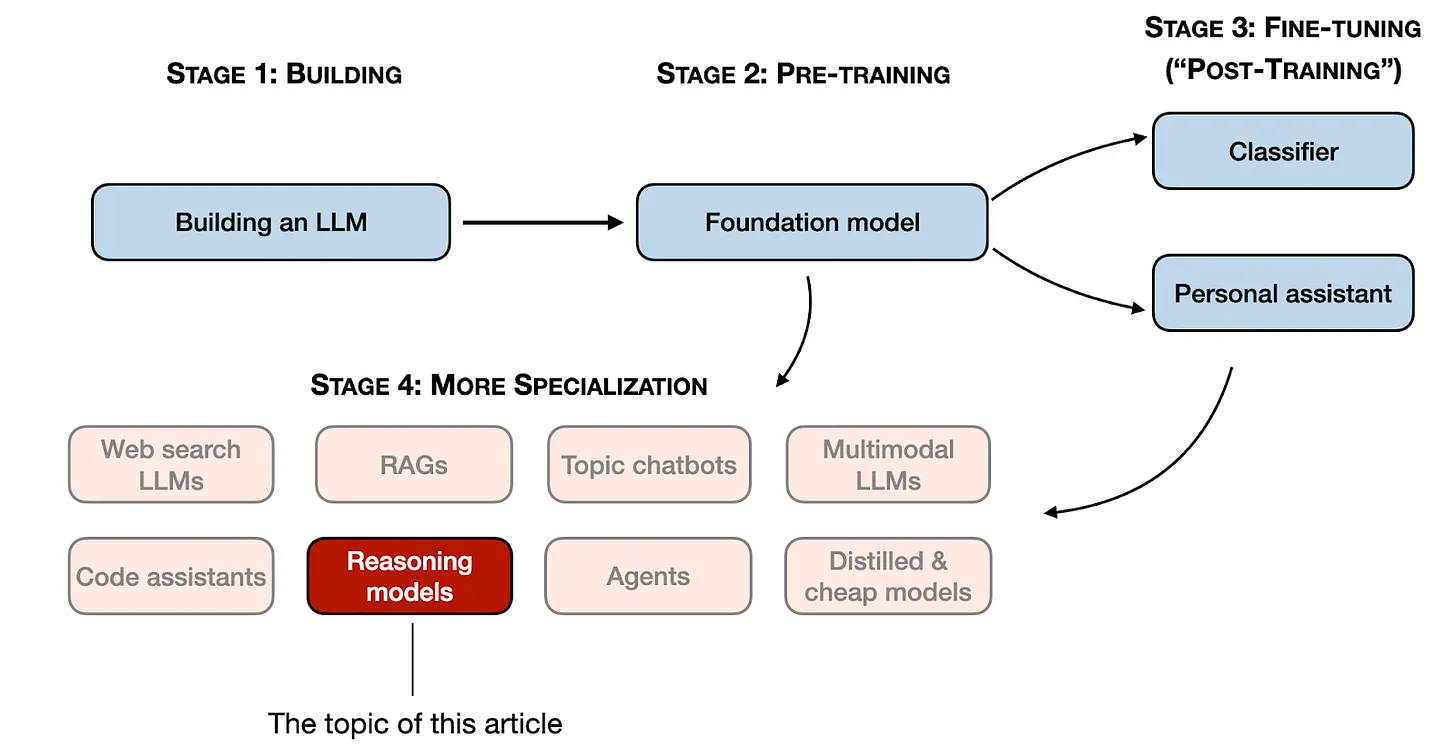
二、什么时候用推理模型
并不是所有问题都需要用到推理模型。一些简单的或是摘要、翻译、或是基于知识的问答任务并不需要用到推理模型,不是因为推理模型回答不了这类问题,而是推理模型在推理时通常计算成本更高,耗时也会更长,而输出内容也相对较复杂,甚至有时还会因为“过度思考”而导致错误。一般来说,推理模型适合数学、编程等逻辑性较强的问题。
三、如何构建推理模型
通过对 DeepSeek R1 论文的解读,以及对 OpenAI o1 的推测,Sebastian 总结了四种构建推理模型的技术。
1) 推理阶段扩展(Inference-time scaling)
一般是在推理阶段通过提示词工程(Prompt Engineering)来实现,比如“思维链提示词”(CoT),在输入提示词中增加让大模型“逐步思考”(think step by step)等词语,鼓励大模型在生成过程中输出中间推理步骤。这种方法往往会在一些需要演算策略等类型问题上奏效,如下图所示:

除此之外,还可以采取其他推理阶段的扩展方法,比如让LLM生成多个答案通过投票来选出最佳结果,或采用“集束搜索”(beam search)等搜索算法来生成最优答案。
2) 纯强化学习(Reinforcement Learning, RL)
早在ChatGPT时期,强化学习便被用来作为 ChatGPT 背后 Instruct 模型的训练方法,而 DeepSeek R1 论文中也显示:推理能力可以从强化学习中自发涌现。与 ChatGPT 所使用的“基于人类反馈的强化学习”(RLHF)不同,RLHF 侧重于基于人类偏好来调整 LLM,而 DeepSeek R1 所用的强化学习则设计了另外两种奖励机制:“准确性奖励”(accuracy reward)和“格式奖励”(format reward)。准确性奖励使用确定性系统评估数学类等问题的回答,比如通过LeetCode编译器验证代码类问题的正确性。格式奖励则以来另一个大模型作为评判者,以确保回答符合预期格式,比如将推理步骤放置于 <think> 标签内。
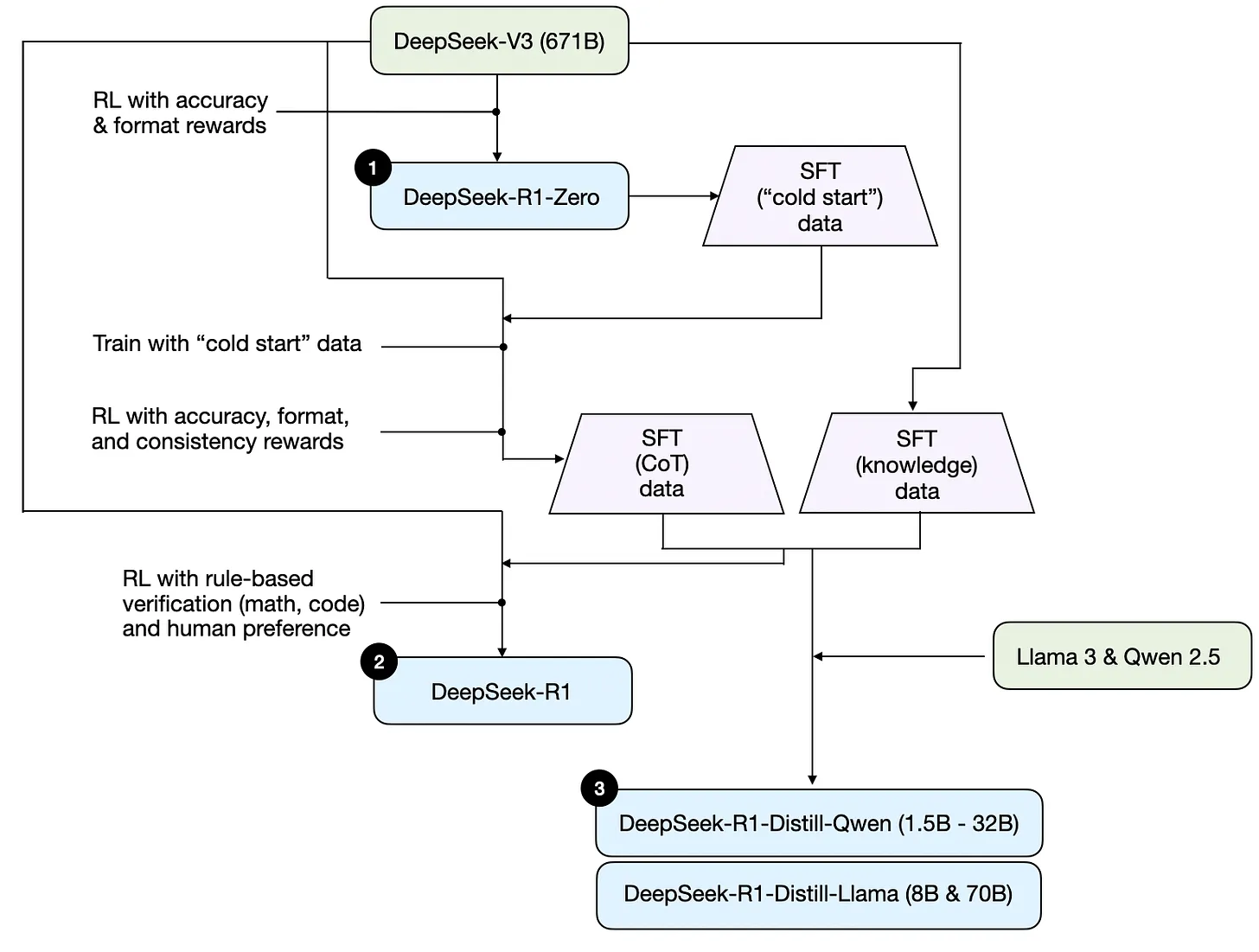
DeepSeek 基于 DeepSeek V3 671B模型,采用纯强化学习训练得到 DeepSeek-R1-Zero 模型,如下图示:
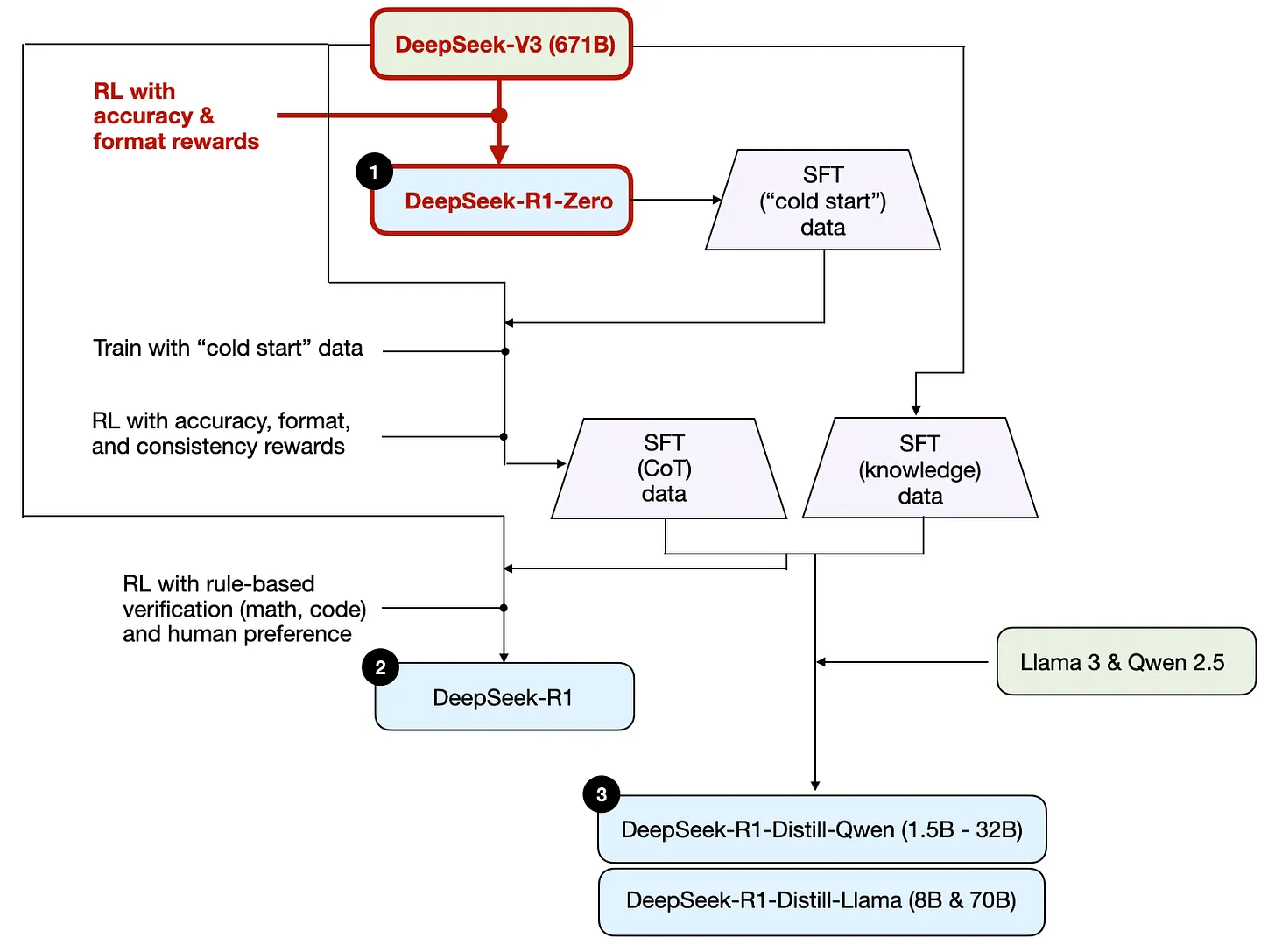
3) 监督微调与强化学习结合(SFT + RL)
DeepSeek-R1-Zero 并非是 DeepSeek R1 系列性能最好的模型,DeepSeek 在此模型基础上增加了额外的监督微调(SFT)和强化学习(RL),训练得到 DeepSeek R1 模型,如下图示:
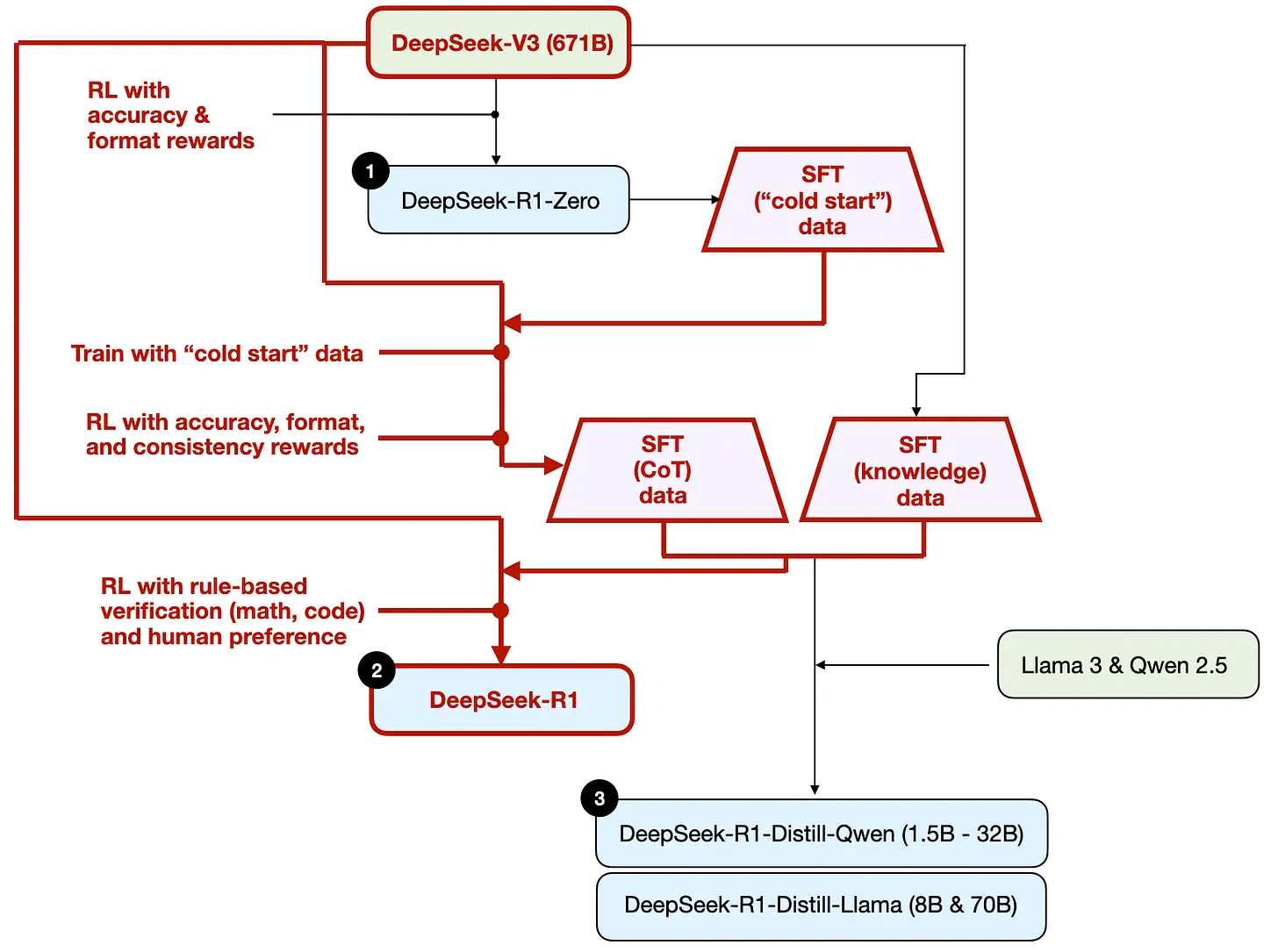
DeepSeek 团队先是用 R1-Zero 生成 SFT “冷启动”(cold start, 相当于初始化)数据,用这些数据基于 DeepSeek V3 做指令微调,然后又进行一轮强化学习,在 R1-Zero 使用的准确性奖励和格式奖励基础上,增加了“一致性奖励”(consistency reward),这种奖励机制是为了防止模型在回答中混用多种语言。然后用这种训练出的中间过程模型生成约60万条“思维链”(CoT) SFT 样本数据,另外再用 DeepSeek V3 基础模型生成20万条基于知识的 SFT 样本数据。
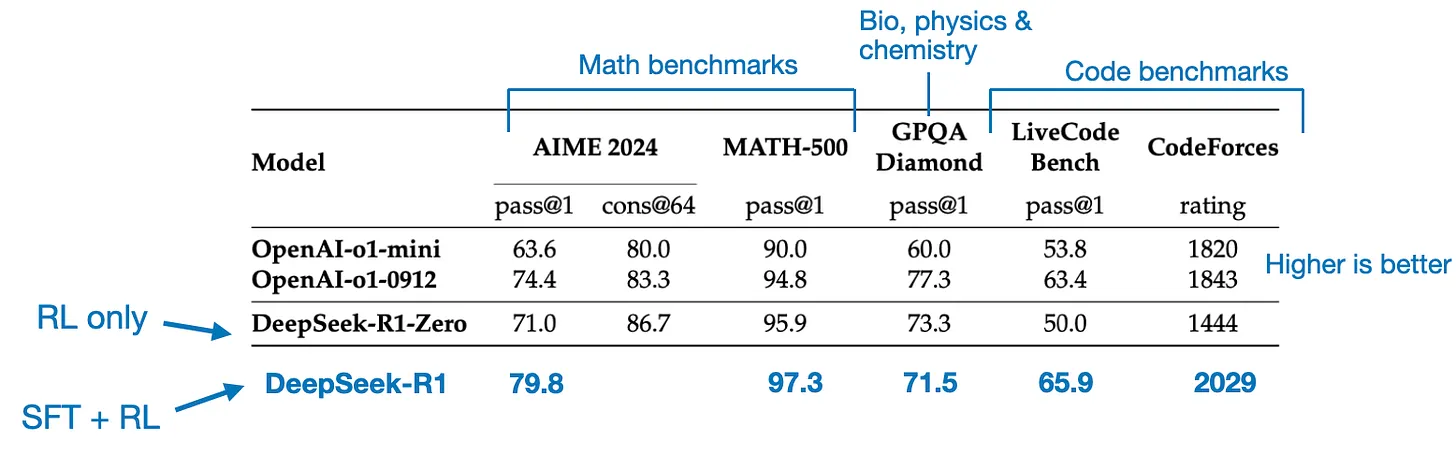
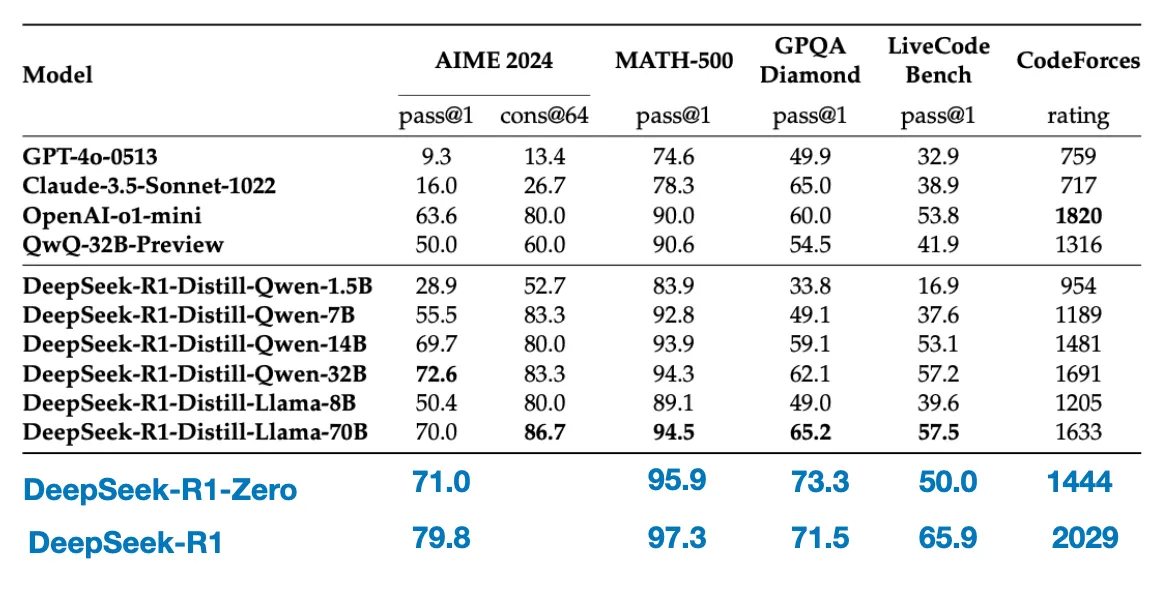
这两种共计80万条 SFT 样本数据被用于对 DeepSeek V3基础模型进行指令微调,之后再进行一轮强化学习。在这轮的强化学习阶段,DeepSeek 使用基于规则的方法为数学、编程等问题提供准确性奖励,而对于其他问题则引入人类偏好奖励。最终得到的 DeepSeek-R1 模型在性能上总体超越了 R1-Zero, 如论文中所附的下表所示:
4) 监督微调(SFT)与知识蒸馏(Distillation)
DeepSeek R1 系列还发布了一系列通过所谓“蒸馏”(distillation)训练得到的较小模型。蒸馏的方法就是用大型模型(如 DeepSeek V3 671B)生成的SFT样本数据,对较小的模型(如 Llama 8B)进行指令微调。DeepSeek 蒸馏模型所用的 SFT 数据如上述 R1 所用 SFT 数据一致,即 DeepSeek R1 中间版本模型生成的60万思维链数据和 DeepSeek V3 生成的20万知识数据。只不过不是基于 DeepSeek V3 而是在 Llama 3 和 Qwen 2.5 上训练,得到 DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-70B 等蒸馏模型。如下图示:
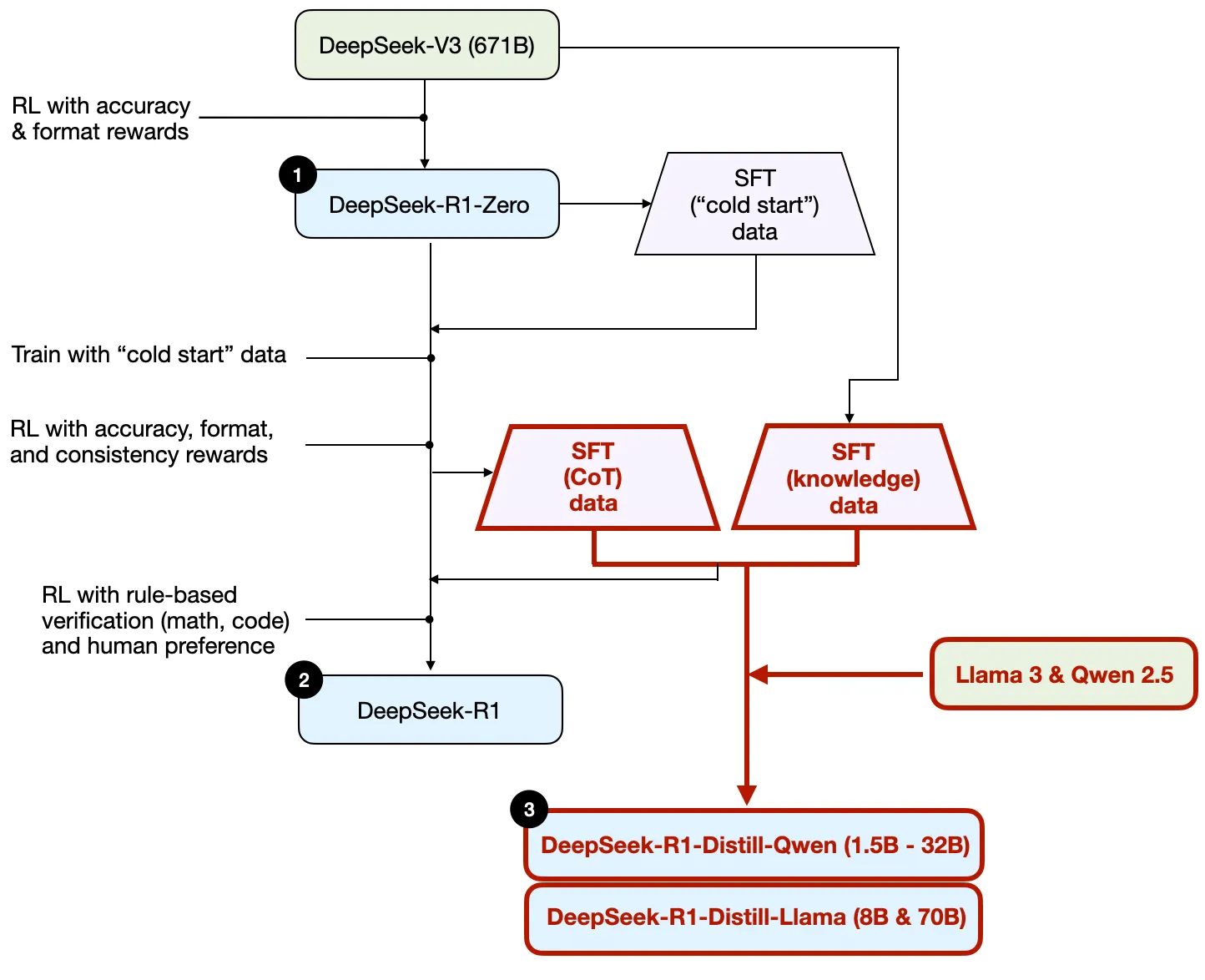
蒸馏模型性能虽然不如 DeepSeek R1,但是相比 R1-Zero,性能却要好很多。而且模型参数相对较小,运行成本也更低。
四种训练方案小结
简要回顾下这四种训练方法。第一种推理阶段扩展无需额外训练,在推理模型实际应用中都或多或少有使用,只不过会显著提升推理成本。而后三种训练方法在 DeepSeek R1 系列模型的训练都有体现。纯强化学习能够让大模型出现推理能力的涌现,这中方法被用来构建 R1-Zero, R1-Zero 不仅用来验证强化学习的效果,也被用来生成 R1 的冷启动数据。监督微调+强化学习的结合是训练推理模型的首选方案,这种方法也被用来构建 DeepSeek R1 模型。而蒸馏方案则用来构建较小的推理模型,适合低成本场景。
四、推理模型的未来
在了解了推理模型的构建过程后,可以看到,强化学习是大模型涌现推理能力的关键;而强化学习和 SFT 结合,可以得到性能更强的推理模型。Andrej Karpathy 说“强化学习很糟糕,但其他方法更糟。”在当前阶段,强化学习虽然存在一些效率问题,但却是让大模型学会推理决策的最优方法。
回到 Lukasz Kaiser 的演讲议题《推理模型的历史、现在与未来》,其英文原名是 Reasoning Models: What's Great and What's Next? . Lukasz 回顾了 Transformer 的历史,在 Transformer 之前,AI 业界研究的是循环神经网络(RNN),它无法并行处理词语序列,记忆力有限,Lukasz 形容它就像是一只在词语序列上行走的蜗牛。而 Transformer 的诞生解决了这严重的效率问题,它就像一只把过往知识都背在壳里的蜗牛,通过并行处理和注意力机制,极大的增强了模型的性能。
不过面对数学、编程等复杂任务领域,仅依赖记忆是不够的,还需要学习推理策略。这就是推理模型要解决的问题。演讲中举了个例子,问旧金山动物园几点开门?Transformer 模型的做法是在训练时记住了所有动物园的开门时间(信息可能会过时),而推理模型则是学会了查询搜索引擎的策略能力,调用搜索引擎并分析查询结果而给出答案。从 Transformer 到推理模型是从“知识记忆”到“方法学习”的本质转变。
为了与 Transformer(转换器)对应,Lukasz 把推理模型叫作“Reasoner”(推理器),而他预测推理模型的下一个进化方向便是 “Researcher”(研究器)。关于这个 Researcher, Lukasz 是这样描述的:“想象一下,一个模型不再是单一的思考者,而是能够并行启动成千上万个‘思维线程’的庞大研究系统,它能从任意信息中学习,而不仅仅是那些我们能够事先验证的数据。”这并非空想,实际上,Lukasz 的 OpenAI 同事已经在刚发布的 GPT-5-Pro 上验证,他选取了一篇今年的数学论文,使用 GPT-5-Pro 尝试解决其中一个明确且尚未解决的开放问题,17分钟后,GPT-5-Pro 给出了证明,且比论文中的方法更优。
我并非AI或大模型专家,在这里仅将学习 Sebastian Raschka、Lukasz Kaiser 的博客和演讲做个笔记总结。至于推理模型的未来是否如 Lukasz Kaiser 所预言,我不得而知。而至于未来的推理模型应该怎么构建,我就更不得而知。我只是隐隐约约地联想到强化学习之父 Richard Sutton 在《苦涩的教训》一文中的观点:人们总是试图为AI构建逻辑规则,这种方法在短期内常常有效,而看起来相当“聪明”,但当计算能力提高、数据增多、学习算法更强时,依赖数据和学习的通用方法总能超越人类的“聪明”设计。我们应该从痛苦的教训中学到,通用方法的力量是巨大的,那是随着计算量的增加而持续扩展的方法。目前看来能够无限扩展的两种方法是搜索和学习。
参考
- Understanding Reasoning LLMs, Sebastian Raschka, 2025/02
- 《万字解密ML 2025大会首日最强思辨现场》 CSDN, 2025/10
- The Bitter Lesson, Richard Sutton, 2019/03
我思,故我在。
—— 笛卡尔
